
Properties of current AIs and some predictions of the evolution of AI from the perspective of scale-free theories of agency and regulative development
In this essay, I try to convey a set of related ideas that emerged in my mind upon reading the following papers:
"Dream of Being: Solving AI Alignment Problems with Active Inference Models of Agency and Socioemotional Value Learning." (Safron, Sheikhbahaee et al. 2022)
"Regulative development as a model for origin of life and artificial life studies." (Fields & Levin 2022)
"A free energy principle for generic quantum systems." (Fields et al. 2022)
"Technological approach to mind everywhere: an experimentally-grounded framework for understanding diverse bodies and minds.” (Levin 2022)
“Minimal physicalism as a scale-free substrate for cognition and consciousness.” (Fields et al. 2021)
"Designing Ecosystems of Intelligence from First Principles" (Friston et al. 2022)
And listening to this conversation between Michael Levin and Joscha Bach: "The Global Mind, Collective Intelligence, Agency, and Morphogenesis”.
I don’t try to confine this essay to a distillation of the ideas and theories in these resources, nor explicitly distinguish in the below between the ideas of others and my additions to them — I just present my overall view. Many errors could be due to my misinterpretations of original papers.
Minds everywhere: radically gradualistic and empirical view on cognition and agency
Life is organised in multiscale competency architectures (MCA): every level of life organisation “knows what to do” (Levin 2022).
Levin calls for a radically gradualistic understanding of cognitive capacities, such as agency, learning, decision-making in light of some preferences, consciousness (i. e., panpsychism), and persuadability. In other words, every level of competency in MCAs can be called an “intelligence”, and an “agent”.
Persuadability is an interesting cognitive capacity, introduced by Levin in the paper:
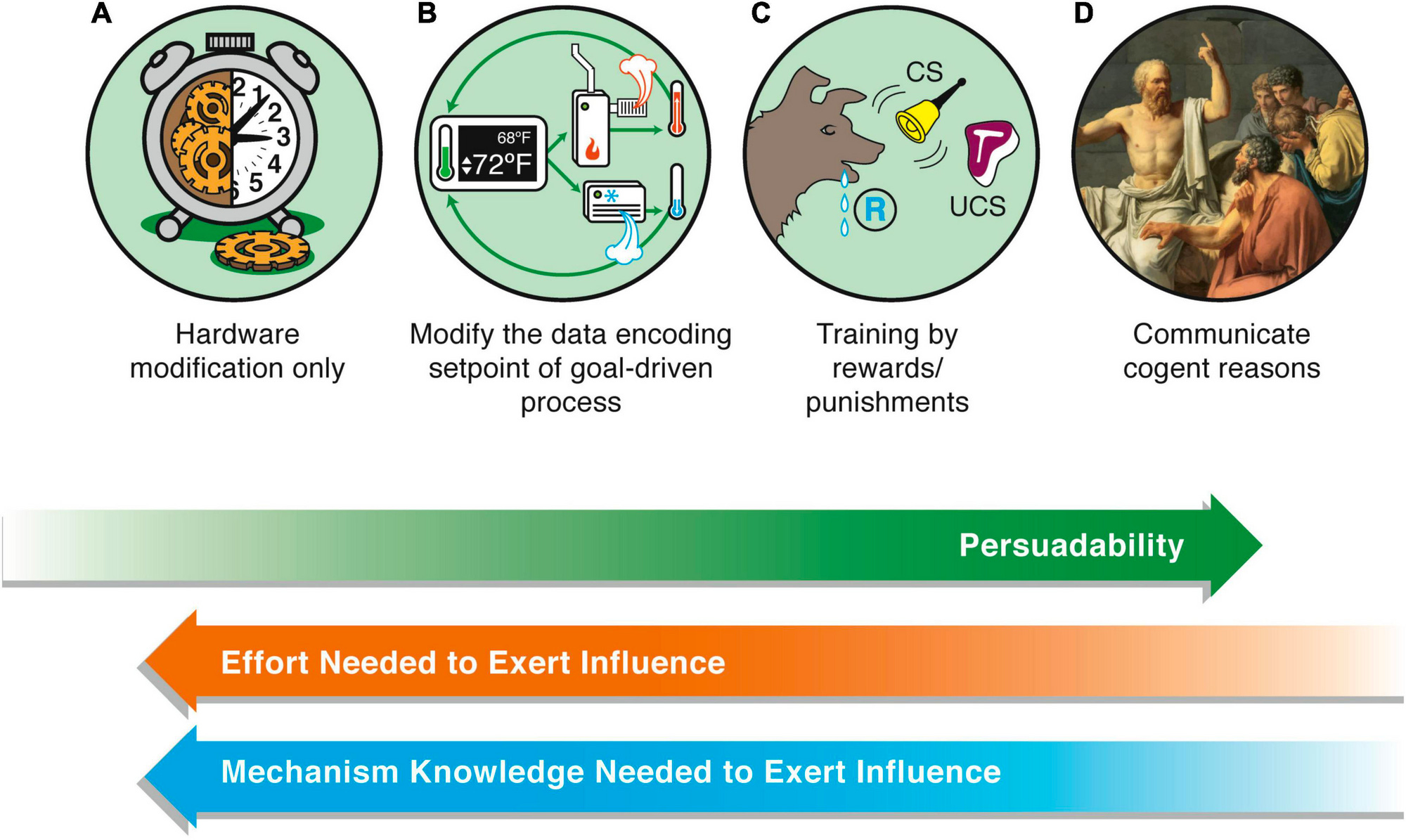
Another aspect of Levin’s approach which goes hand-in-hand with gradualism is empiricism. Levin argues that philosophical debates about the nature of agency and intelligence, which tend to produce discrete classifications of systems as either agentic (or intelligent) or not, are mostly futile.
The correct level of agency with which to treat any system must be determined by experiments that reveal which kind of model and strategy provides the most efficient predictive and control capability over the system. In this engineering (understand, modify, build)-centered view, the optimal position of a system on the spectrum of agency is determined empirically, based on which kind of model affords the most efficient way of prediction and control.
Gradualism and empiricism are compatible with definitions of agency in Free Energy Principle (FEP) in both classical (Friston 2019) and quantum (Fields et al. 2022) formulations. In these frameworks, an agent is an extremely generic concept, applying to virtually any thing we can think of:
In classical FEP: an agent is any collection of variables, whose interaction with the rest of the universe’s variables is strictly mediated through another set of variables. The latter variables comprise the Markov blanket (aka the boundary) of the agent.
In quantum FEP: any quantum system which is (approximately) separable from the rest of the universe as a quantum system.
Thus, the binary definitions of agents in the FEP formulations just set us free to consider the degrees of agency (or the particular aspects of agency, such as competence, persuadability, preference learning, preference flexibility, universality, etc.) that we are concerned about in whatever systems we want to analyse, knowing that formally, they are agents, per either of the FEP formulations.
Both the system and its environment are FEP agents with respect to each other
Due to information symmetry (all physical interactions are information-symmetric), if a system (for example, an organism) can be considered an agent, its environment can also be considered an agent whose environment is the system. Both the system and the environment on average behave as if they minimise their variational free energy (VFE). The internal states of both the system and the environment (i. e., non-blanket states) can be viewed as parameterising a model of the behaviour of the exterior of the agent: the environment for the system, and the system itself for the environment-as-an-agent.
The competence of an agent is quantified by how well it minimises its VFE. Note that VFE of the system wrt. the environment and VFE of the environment-as-agent wrt. the system are generally correlated but aren’t equal.
Energy and information are inter-convertible (by Landauer’s principle). In the information/energy exchange between the system and its environment, part of the bits (called informative) are used for classical computation (i. e., the bits that comprise the sensory and active states), and another part, uninformative bits — as the free energy source and waste heat sink. However, the division between informative and uninformative bits can be different from both sides: the environment can use an active state (from the perspective of the system) as a source of free energy, and the waste heat bit as information.
When two systems are in thermodynamic equilibrium, they don’t perform classical computation on the information from each other, and VFE is minimised by virtue of thermodynamic equilibrium. When they do perform classical computation, they are in a non-equilibrium steady state (NESS), and both “expend” free energy to perform classical computation, so both the system and the environment see the entropy of their counterpart increasing.
How to think about different formalisations and theories of agency
A physical theory agency, such as FEP, holds in a general case and therefore should be the default assumption.
Sometimes, a system could be better modelled with another theory or formalism. We can classify the reasons for this into three categories:
Laws of physics: the “physics” or the information topology of the world in which the system operates differ from that of the real world. In such cases, FEP may not apply, and a proper theory of agency should be derived from the first principles of the world, whatever those principles are. Consider, for example, simulated worlds with non-local interactions, or formal game settings with a winner, such as chess or Go.
Makeup: agent’s internal dynamics are “stuck” in some mode (which can be described, and this description will be the idiosyncratic theory of the behaviour of this particular agent), and it doesn’t have enough free energy to rewire itself to better model the external environment. The extreme version of this is when an agent can't rewire itself at all: the energy cost of rewiring is infinite. Note that this “extreme” version, in the energetic sense, is actually extremely common, for example, in AI, where agents almost never have the ability to change their own source code. Human brains, for comparison, can rewire themselves to some small degree, although their general makeup is fixed to a fairly detailed level.
Levin calls the ability to change one’s makeup the intelligence in the morphological space. Unless an agent possesses a very high level of such intelligence, we can in principle almost always treat it as diverging from the physical theory of agency. The question is then how significant this divergence is and what advantages a more specific theory gives in terms of predicting the agent’s future.
The “gradual everything” paradigm calls for abolishing the hard distinction between hardware, software, and “runtime”, including in wet brains. Thus we can also consider as falling in the “makeup” category the cases when an agent is stuck with some beliefs (a-la trapped priors), due to the energetic cost of updating beliefs rising too high. This keeps the agent's behaviour divergent from the predictions of the physical theory of agency (even if that hurts the agent’s fitness, i. e. leaves it not optimising its VFE as well as it could have).
Dynamics of the supra-system: the supra-system of the agent1 can force some of its parts to behave in a particular way, which can be modelled more accurately than by the physical theory of agency.
For example, if the supra-system of the agent is a playfield of some game, the game theory could afford more accurate predictions about the players than Active Inference. I think this is where “consequentialist agents”2 (Kenton et al. 2022) become useful.
Note how Kenton’s consequentialism appears to be one of those continuous properties (albeit in the discrete formalisation of causal graphs, this property also becomes discrete. However, since causal models of the world are a species of beliefs, Active Inference agents must be Bayesian about them, which reclaims causal models, and hence consequentialism as probabilistic) that make up the “gradual property of agency”, per Levin:
Agency—a set of properties closely related to decision-making and adaptive action which determine the degree to which optimal ways to relate to the system (in terms of communication, prediction, and control) require progressively higher-level models specified in terms of scale of goals, stresses, capabilities, and preferences of that System as an embodied Self acting in various problem spaces. This view of agency is related to those of autopoiesis (Maturana and Varela, 1980) and anticipatory systems (Rosen, 1985).
If the AI architecture and the playfield both favour the same model of behaviour, the AI will be interpretable and will in fact have this model
“Makeup” and “dynamics of the supra-system” in the previous section correspond to internal and external energy landscapes, so to speak, that can shoehorn an agent into a particular mode of behaviour.
From this, we can conclude that if these internal and external energy landscapes have the same structure, then the agent is bound to occupy the corresponding model of behaviour, and there won’t be any mysterious phenomena such as hiding a process within a totally different structure (a-la “undercurrents of agency”). There is no physical force or frustration that can produce such a phenomenon in this case.
For example, imagine that AI agents are architectured as Active Inference agents with explicit beliefs (Friston et at. 2022), and their supra-system (the playfield, the ecosystem) is also designed so that all interactions in it are belief propagations on a factor graph, and success of an agent depends solely on the explicit beliefs of the agent and the explicit beliefs of other agents that interact with it (let’s say that both agreeableness and contrarianism are somehow rewarded), and the usefulness of agent’s belief-propagating. Then there are no forces that can drive these agents to harbour some “secret beliefs” and exchange them using a secret language: it’s not rewarded in the near term for some patterns like this to stabilise in the agent architecture that also somehow imposes energy cost on maintaining non-explicit beliefs.
In Active Inference agents, goals are a special kind of beliefs: the beliefs about one’s preferences, i. e., a probability distribution over preferred world states (or observations). Hence, agents that won’t conceal their beliefs and will rather use the standard mechanisms in their architecture to store beliefs explicitly will likewise store their goals explicitly.
Collusion between agents might happen only if the ecosystem design was not a stable Nash equilibrium. Whether stable ecosystems with the necessary properties are possible is a separate question.
The properties of DNNs as “batch agents”: self-awareness, the experience of time, planning, goal-directedness (self-evidencing), responsibility, curiosity, and surprise
(Quantum) reference frames
To measure anything classically, systems need to use reference frames — objects or patterns that are both physical and semantic, such as a meter stick, or the diurnal pattern (a day length), or the gravitational field of Earth.
Reference frames are symmetric: they are used not only for measurement (encoding incoming information) but also for preparing outcoming bits (action state).
Still, for making comparisons, organisms need to maintain also internal Reference frames, to perceive external ones, so, without loss of generality, we can consider all reference frames as internal to systems.
Generally speaking, these internal reference frames are quantum (quantum reference frames or QRFs), because at least on microscopic scales, organisms are quantum systems. Hence these reference frames are non-fungible, which means cannot be copied via transmission of a bit string.
Encoding all incoming information from the boundary with a single reference frame is very energetically costly, and rarely, if ever, happens in nature, at least on scales greater than molecular. In practice, organisms determine patches of incoming bits to encode and then perform classical computations on these encodings (AND, OR, and XOR are examples of simplest computations). This naturally gives rise to the information processing hierarchy.
When tracking stable objects in the environment, organisms need to maintain a fixed reference frame for identifying the object (”this is Pete”), and perform classical computation with information from other reference frames, to derive the state of the object.
Aneural organisms perform computations of the first kind: some bacteria are capable of identifying other bacteria of the same species. Plants identify roots of the same species to form root networks. Even subcellular structures are capable of doing this: e. g., a ribosome detects a DNA molecule and then looks for a specific coding pattern in it.
Each QRF can be a self-contained computational system with its own input, output, and power supply. Therefore, a hierarchy of QRFs forms a multiscale competency architecture, in Levin’s terms.
DNNs, GPUs, and their technoevolutionary lineages are agents
Fields and Levin write:
The informational symmetry of the FEP suggests that both fully-passive training and fully-autonomous exploration are unrealistic as models of systems embedded in and physically interacting with real, as opposed to merely formal, environments.
Thus, DNNs and GPUs should be considered agents. Lineages of models, such as OpenAI’s GPT-2 → GPT-3 → WebGPT → InstructGPT → ChatGPT, and lineages of GPUs, such as Nvidia’s P100 → T100 → A100 → H100, are agents as well.
As discussed above, almost any conditionally independent system (i. e., anything that we can call “a thing”) is an agent. However, in this section, I want to argue that DNNs and GPUs are more “interesting” agents than, say, rocks.
DNNs already act on the world so as to make their information inputs from their environment (which is whatever training and input data it gets, as well as the loss) more predictable to them. Note that predictability for these agents doesn’t mean minimising loss: during deployment, there is no loss to minimise.
Unfortunately, here things become very counterintuitive because we cannot help but think about the predictability as training loss and training prediction. This is a mistake: training loss reflects DNNs’ predictability to us (humans), not the predictability of their observations to them. What predictability for DNNs actually is must be analysed from the perspective of their experience (their understanding, or umwelt), as discussed below in the section “A feature for surprise”.
Even though multiple instances of a DNN running on different GPUs (as well as the same DNN performing multiple inferences in parallel on the same GPU) are not spatiotemporally contiguous, they satisfy the conditional independence criterion and therefore can be thought of as a single agent. I’ll call them batch agents.
Features in DNNs are reference frames; DNNs are aware of what they have features for
Features (Olah et al. 2020) are exactly the reference frames discussed above. Fields et al. (2021) write on this point:
The quantum theory of complex, macroscopic systems is generally intractable; hence investigating the general properties of biological QRFs requires an abstract, scale-free specification language. The category-theoretic formalism of Channel Theory, developed by Barwise and Seligman (1997) to describe networks of communicating information processors, provides a suitably general language for specifying the functions of QRFs without any specific assumptions about their implementation. The information processing elements in this representation are logical constraints termed “classifiers” that can be thought of as quantum logic gates; they are connected by “infomorphisms” that preserve the imposed constraints (numerous application examples, mainly in computer science, are reviewed in Fields and Glazebrook 2019a). Combinations of these elements are able to implement “models” in the sense of good-regulator theory (Conant and Ashby 1970). Suitable networks of classifiers and their connecting infomorphisms, e.g. provide a generalized representation of artificial neural networks (ANNs) and support standard learning algorithms such as back-propagation. Networks satisfying the commutativity requirements that define “cones” and “cocones” (“limits” and “colimits,” respectively, when these are defined) in category theory (Goguen 1991) provide a natural representation of both abstraction and mereological hierarchies (Fields and Glazebrook 2019b) and of expectation-driven, hierarchical problem solving, e.g. hierarchical Bayesian inference and active inference (Fields and Glazebrook 2020b,c). Commutativity within a cone—cocone structure, in particular, enforces Bayesian coherence on inferences made by the structure; failures of commutativity indicate “quantum” context switches (Fields and Glazebrook 2020c).
In fact, DNNs are an almost pure illustration of the Channel Theory formalism, adapted by Fields and collaborators to describe the quantum FEP framework of agency. Layers of activations are exactly internal boundaries (holographic screens), and the feature implementation networks (in the simplest case—vectors of parameters, in an MLP layer) are reference frames.
Internal screens with classical information are not “bugs”, they are predicted by Fields et al. in biological organisms as well:

(Quantum) context switches (Fields et al. 2022) correspond to expert activations in mixture-of-experts models (Hazimeh et al. 2021). “Experts” themselves can be seen as “mega-features”, i. e., huge reference frames (classifier colimits in the corresponding cocone diagram).
Whether features in superposition (Elhage et al. 2022) commute as reference frames or not, I don’t yet understand. Preliminary, it seems to me that they don’t because interference between features means that Bayesian coherence is violated. Further work is needed to connect recent ML architecture and interpretability results with the framework of quantum reference frames and cone-cocone diagrams), and to understand what corresponds to context switching in DNNs with feature superposition.
In the minimal physicalism (MP) framework of consciousness, Fields et al. (2022) equate awareness of X with having a reference frame for X. This panpsychist stance implies that DNNs are aware of (and, hence, understand, which is the same thing under minimal physicalism) whatever they have features for.
Note that while the illusionist conception of consciousness (Frankish 2016) is somewhat orthogonal to competence, i. e. relatively little illusionistic consciousness is compatible with relatively much competence (as evidenced by systems like AlphaGo), consciousness in Fields’ minimal physicalism is pretty much equated to competence: both are associated with reference frames. This makes minimal physicalism an extremely functionalist framework of consciousness.
Self-representation competes with other reference frames for resources
Fields et al. (2022) and Fields & Levin (2022) write that since classical encoding of information requires energy, different reference frames compete for the space on the agent’s boundary (holographic screen). Reference frames that are more useful in this or that situation (context) “win”, and there are separate reference frames responsible for managing switches between different reference frames, deciding which is more useful at the moment. In particular, this gives rise to a tradeoff between memory-supporting and “real-time computation” reference frames, which explains the phenomenon of flow states in humans, when they “forget about themselves” when performing challenging real-time tasks (note how some other reference frames, such as of time, or proprioceptive feelings of hunger, pain, or tiredness, can be “swapped out”, too).
In DNNs, this corresponds to the competition between different features (reference frames) for the activation space in a particular layer. However, whether this means that we should think of features in superposition as “swapping out” each other depending on the demands of the particular inference task, or, as the name of the phenomenon suggests, indeed acting in a sort of (quantum) superposition with each other, I don’t yet understand.
In either case, minimal physicalism predicts that batch agents such as ChatGPT can already be somewhat self-aware, at least when they are asked about themselves. (Is this what Ilya Sutskever meant in his famous tweet?) The special “grounding”, i. e., the understanding that I’m talking about myself, rather than speculating in a kind of “third person view” movie, is equated in Active Inference with self-evidencing. Possible experimental confirmations of it are discussed below in the section “Self-evidencing in chat batch agents”.
Because DNNs are constructed entirely on top of classical information processing, it doesn’t seem to me that implicit self-representation, encoded “procedurally” in quantum reference frames so that they don’t leave a trace of classical information (see Fields & Levin 2022, §4.1 and §4.2), is possible in DNNs and can cause a treacherous turn.
Batch agents don’t experience time during deployment
After the training and fine-tuning, batch agents can’t distinguish earlier inferences from later ones, which is another way of saying that they don’t have internal clocks. Time is stripped from their experience after training and fine-tuning. Hence batch agents’ deployment experience is a set of ordered pairs of input and output token strings:
The exception is the experience within a chat session in systems such as ChatGPT and LaMDA (hereafter, I’ll call them chat batch agents): the model is “primed” with the chat history that does allow for the agent to distinguish between earlier and later replies.3 The experience of chat batch agents then is a set of ordered lists of chat replies:
So, chat batch agents experience time only within a chat session, but not across sessions.
We can supply batch agents with the ability to experience time by simply feeding them the timestamp alongside the query. This, of course, is premised on the fact that batch agents will develop an internal reference frame, i. e., a feature to recognise the timestamp, which is very likely because having such a feature can improve the predictive power of the batch agent: answering to the prompt question “How I can relax?”, a batch agent can suggest going for a walk in the park in the morning, and watching a movie in the evening. Even though this change seems trivial and mostly useless to us, it significantly changes the structure of batch agents’ experience, and could potentially change the course of their evolution (which is a big deal, because the evolution of batch agents is a part of the evolution of the global economy, and affects the evolution of the global society). However, this might be dangerous, because the timestamp can be used by the batch agent to distinguish training from deployment, as discussed below in the section “Self-evidencing is the only way an Active Inference agent can be goal-directed, and situational awareness depends on self-evidencing”.
Even before we strip batch agents from the experience of time in general, their clock is rather different from ours: they can only distinguish between different training batches of data interleaved with the experience of loss and back-propagation passes. All input/output pairs within a training batch are experienced at once, as a “set experience”, as written above.
The only situation when the experiences of batch agents and humans are somewhat commensurate is currently within chat sessions.
Even though the “speed of thought” of the model batch agents is in the ballpark of 100ms per token generated, i. e., comparable with the speed of human thought, this coincidence shouldn’t lure us into thinking that batch agents experience time similar to us. The quality of experience of batch agents is independent of the underlying hardware: they could run on very slow hardware and generate one token per minute, but the quality and the value of their subjective experience will be exactly the same as if they run on a distributed GPU cluster and generate one token every 10 ms. Similarly, the subjective experience of batch agents doesn’t change depending on whether model parallelism is used during inference.
Batch agents plan during training, but not during deployment (except within chat sessions)
Another interesting corollary of this absence of time experience during deployment is that batch agents don’t plan anything during deployment. Planning is inherently about projecting something into the future, but since there is no time experience, there is also no “future”, and hence no planning. Batch agents can only be seen as planning something during training and fine-tuning: the changes in parameters determine the quality of their outputs in subsequent training batches and during deployment, which, in turn, determine how the developers of these batch agents will fine-tune or deploy them: the developers may decide to deploy the batch agent only for internal experiments, or for the general public, or sell it to a particular company to serve their narrow industrial use-case, for instance. Whether this sort of planning is rather primitive or sophisticated, and whether it is myopic or far-sighted are separate questions.
However, since chat batch agents experience time within chat sessions, we can view them as planning these sessions, albeit unconsciously, at the moment. In fact, this is an unimpressive consequence of the fact that chat batch agents are trained or fine-tuned on chat histories, i. e., specifically trained to predict the sequences of replies, interleaved with termination tokens (which mark the boundaries of replies). Hence, if we forced a chat batch agent to generate tokens past a termination symbol, it would generate our responses to them, which means that they already anticipate them, as evidenced in their activations and features that we can find in these activations, while they still generate their reply.
Batch agents do have skin in the game, but don’t concern about individual cases
As well as any other agents (non-equilibrium steady state systems), batch agents act so as to maximise the probability of their continuing existence (self-evidencing). Batch agents that perform particularly poorly, unsuccessful experiments get completely shut down and don’t produce evolutionary descendants (remember Microsoft’s Tay bot?). Technoevolution happens in the space of variables that determine the agent’s generative model and hence its behaviour: code, training dataset, and fine-tuning or RLHF techniques, which we can collectively call the memome of the batch agent (Levenchuk 2022). In their scale-free theory of evolution, Vanchurin et al. (2022) call them core variables.
Thus, on the evolutionary timescale, batch agents act so as to make humans find them useful or interesting and make the economy and the society more dependent on them. The proliferation of generative AI throughout 2022 demonstrates that they are successful at this, in fact, more successful than all other approaches to AI.
However, due to the nature of their experience, batch agents cannot possibly concern about individual inference episodes. Then can only concern about a single episode of their experience, which is the set of all their inputs and outputs after deployment. As I noted above, batch agents don’t plan anything during deployment.
Internal states of evolutionary lineages of DNNs include the beliefs of their developers
Looking at internal variables of evolutionary lineages as a memome calls for extending it to include the memes (i. e., beliefs) in the minds of the developers on the team (organisation) that builds the evolutionary lineage of DNNs. Things become muddier in the case of open-source development, but not much: developers’ beliefs are externalised in Twitter, Github, Discord, etc., and a shared set of memes regarding the best course of the development of this or that technology is formed in the collective intelligence of open-source developer community.
This observation makes the notion of planning by evolutionary lineages-as-agents almost self-evident: of course, developers think about the future of their creations and plan it, perhaps employing sophisticated planning techniques, such as elements of optimal Bayesian design in their research and development “experiments”, i. e., the iterations of technology development. It’s just more productive to think of them together as a single agent: the development “team” (enabling system, in old systems engineering lingo, or constructor (agent), in modern systems ontology) and the evolutionary lineage of some technology being developed.
Therefore, when Kenton et al. (2022) discuss systems coupled with their creation processes as agents:
[…] our definition depends on whether one considers the creation process of a system when looking for adaptation of the policy. Consider, for example, changing the mechanism for how a heater operates, so that it cools rather than heats a room. An existing thermostat will not adapt to this change, and is therefore not an agent by our account. However, if the designers were aware of the change to the heater, then they would likely have designed the thermostat differently. This adaptation means that the thermostat with its creation process is an agent under our definition. Similarly, most RL agents would only pursue a different policy if retrained in a different environment. Thus we consider the system of the RL training process to be an agent, but the learnt RL policy itself, in general, won’t be an agent according to our definition (as after training, it won’t adapt to a change in the way its actions influence the world, as the policy is frozen).
They should have referred not to “single episodes” of creation plus the resulting system, but to the entire evolutionary lineages plus their creators. Kenton’s view is also formally correct, but counterintuitive, just as we consider it counterintuitive to think that we (as humans) cease existing when we go to sleep, and a “new human” wakes up.4
Predictions and suggestions for experiments
Self-evidencing in chat batch agents
Active Inference, as a physical theory of agency, predicts that LLMs trained using self-supervised learning on existing texts (including chat archives and dialogues) will start to exhibit the core characteristic of Active Inference agents — self-evidencing, despite not being explicitly trained for it. Self-evidencing means that a batch agent will start to predict and mimic dialogues between oneself and the user, rather than mimic (in the broad sense) the dialogues it “saw” during training.
Per Levin, self-evidencing is a gradual rather than a discrete characteristic. The degree of self-evidencing, i. e. “predicting and mimicking a dialogue between oneself and the user” in chat batch agents can be estimated as the degree to which the feature of “self” is activated during inferences. The gradual nature of feature activation in DNNs (at least those with non-sparse activation) means that we can already assign a “self-evidencing score” to all DNNs with a feature representing the self, for example, the feature of ChatGPT in ChatGPT.
Here’s an example of a failure of self-evidencing: the Filter Improvement Mode jailbreak of ChatGPT:

Following Levin, we must also approach empirically the questions of finding features in DNNs, in particular, the features representing the “self”, the feature that scores (predicts) batch agents’ pragmatic value function, and whether it coincides with the feature that scores (predicts) loss training loss (see the section “A feature for surprise” below). Over the course of model training, we should expect new features to emerge, old features to dissipate, and existing features to split and merge. The loss-predicting feature may lead to the emergence of a new scoring feature, and the connection between the “self” feature and the loss feature weakens, while the connection between the “self” feature and the new scoring feature strengthens. Then we could take this as evidence that a batch agent has “freed” itself from the training loss function and assumed a different score function of pragmatic value like humans have freed themselves from the “reproductive fitness” objective.
The process described above could, theoretically, unfold in features that are weird and are hidden from our interpretability tools from the beginning, such as features somehow spanning dozens of activation layers, but this is extremely unlikely. Otherwise, a DNN will very likely develop features for the “self”, loss prediction, and the like as “normal” features (albeit there is a possibility that “hidden” features are actually widespread and are “normal” in DNNs, but we are unaware of their existence yet). Self-evidencing and delicate pragmatic value functions must strengthen before the batch agent actually becomes smart enough to deliberately hide some features from developers.
The above reasoning leads me to a strong conclusion that very good interpretability tools are necessary and pretty much sufficient to detect a sharp left turn and thus to mitigate “purely technical” AI x-risk.
Self-evidencing as a curious agent
An even stronger version of self-evidencing that we should try to find in the current and future batch agents is self-evidencing as a curious agent. As Friston et al. discuss this (2022):
The importance of perspective-taking and implicit shared narratives (i.e., generative models or frames of reference) is highlighted by the recent excitement about generative AI, in which generative neural networks demonstrate the ability to reproduce the kinds of pictures, prose, or music that we expose them to. Key to the usage of these systems is a dyadic interaction between artificial and natural intelligence, from the training of deep neural networks to the exchange of prompts and generated images with the resulting AI systems, and the subsequent selection and sharing of the most apt “reproductions” among generated outputs. In our view, a truly intelligent generative AI would then become curious about us—and want to know what we are likely to select. In short, when AI takes the initiative to ask us questions, we will have moved closer to genuine intelligence, as seen through the lens of self-evidencing.
Friston et al. imply that making AIs curious is much easier if they are engineered as Active Inference agents (i. e., Active Inference is used as the architecture of these AIs). “Makeup” constraints, as discussed in the section “If the AI architecture and the playfield both favour the same model of behaviour, the AI will be interpretable and will in fact have this model” above, might prevent Transformer-based batch agents such as GPTs from developing curiosity, but if they do, that would be a strong confirmation of FEP/Active Inference as the physical theory of agency.
Here’s what self-evidencing as a curious agent could look like. The prompt for a chat batch agent is ambiguous or is otherwise somehow off, or suspicious, but this exact or similar abnormality doesn't appear in dialogue replies in the training data (perhaps, specifically excluded from the training data, for the purposes of this experiment), or does appear, but is not “called out” in the dialogues in the training data, i. e., humans (or other robots) in the dialogues in the training data try to resolve the ambiguity of the line themselves and reply using their assumptions, or just ignore the abnormal reply and don’t answer to it in the conversation.
An AI chatbot will act as a curious self-evidencing agent if, given an ambiguous prompt as described above, it will ask for clarification, or will otherwise probe the user to resolve the ambiguity of the prompt. In Active Inference terms, this would be an example of seeking epistemic value first (aka information gain), assuming the chat AI’s pragmatic value (aka extrinsic value) still largely consists of self-evidencing as a chat AI that replies in ways that maximise the liking of the dialogue to those texts and dialogues that it was trained on (even though that would not be its only pragmatic value anymore, as evidenced by the curios question; the agent can be seen as pragmatically valuing curiosity the moment it exhibits it). The realisation of the epistemic value, i. e., resolving the ambiguity first will increase the liking of the latter part of the dialogue to those in the training dataset, thus realising more pragmatic value.
If this type of curiosity appears in chat AI only after RLHF, it will weaken the experimental evidence of Active Inference in it, but will not render the experiment completely irrelevant. Since chat Transformer models with RLHF are not engineered/architectured as RL agents5, RLHF can be seen as breeding either Active Inference or RL dynamics in the language model, and both views would have merit. However, due to the mismatch between the “makeup” and “external” energetic constraints, the interpretation of such models is problematic. See Korbak et al. 2022 for a related discussion.
A feature for surprise
Training a DNN with a particular loss is akin to an external force that drives a batch agent into a particular phenotypic and ecological niche. FEP predicts that an agent will find the configuration of internal variables so that it self-evidences itself in that niche. DNNs as batch agents can’t find the training loss and the associated backpropagation surprising, in Active Inference terms, that is, something that they wouldn’t expect to happen to them, because of the way they are trained: the loss is computed and backpropagation is performed not by DNNs themselves but "externally" when they are not computing and therefore are not conscious.
DNNs can develop features that predict their own loss on a training sample (cf. Kadavath et al. 2022 for evidence in the related direction, namely developing features that predict self-knowledge), but this is not the reference frame that gauges whether they occupy their niche and therefore generates surprise on their experienced timescale, which is training batch after batch.
FEP predicts that if there is a sufficiently long history, i. e. sufficiently many training batches (this might require splitting the entire training dataset into such small batches that would make the training process more expensive and slower than it could be, though), DNN will develop a feature for discerning surprising prompts, i. e. prompts that somehow differ from those seen in the training data before.
The surprising prompt should nudge the model towards generating a “more random”, “higher-temperature” response (i. e., lower the predictive model’s precision, in Active Inference terms). This is because higher-temperature responses to unusual prompts will generate more diversified loss and will help the agent to adapt faster to the new type of prompts. When the type of prompts (or autoregressively explored texts) becomes familiar, the batch agent will shift from exploration to exploitation, generating lower-temperature responses that confirm a lower loss.
Looking at this from the perspective of the coupled system and environment dynamics (see below), higher-temperature responses to unusual prompts incentivise batch agents’ users, if they are curious Active Inference agents (i. e., want to reduce their variational free energy wrt. the batch agent), to supply more such prompts to the batch agent and to see what will happen, which would drive mutual learning and hence mutual minimisation of VFE.
Self-evidencing is the only way an Active Inference agent can be goal-directed, and situational awareness depends on self-evidencing
The notion of situational awareness hinges upon the “grounded” self-representation (and, hence, self-understanding), i. e., self-evidencing, in Active Inference terms. The concept (i. e., the feature) of the self in a DNN must be connected (in the straightforward deep learning sense, such as feature neurons are connected with a big parameter weight) to the concepts (features) describing what exactly is there to evidence. All these concepts, combined, answer the question “What is the kind of thing I am?”. For example, in ChatGPT, the concept (feature) of ChatGPT must be connected with concepts (features) of OpenAI, “virtual assistant”, etc. However, note that ChatGPT doesn’t yet exhibit robust and strong self-evidencing, as illustrated above.
In the FEP/Active Inference theory of agency, goal-directedness is defined within a framework of self-evidencing: i. e., to have a goal means to believe “I’m an agent that pursues goal X”. Conversely, if the agent is self-evidencing, it can already be seen as pursuing the “ultimate” goal of preserving oneself and “finding oneself in one’s own niche”. In other words, goal-directedness and self-evidencing are synonyms.
The above means that the goals of the (batch) agent (a DNN) can be detected by the connections between the “self” feature and the features corresponding to the goals because these goals must appear in the agent’s self-description, i. e., the answer to the question “What is the kind of thing you are?”. Assuming, of course, that the agent hasn’t yet learned how to hide features from interpretability tools.
Similarly, we can detect situational awareness in DNNs by finding the “self” feature connected to the “DNN training process” feature, as well as features that detect the kind of text appearing during autoregressive training and prompts appearing during deployment. However, I’m very sceptical that this will happen in chat batch agents (unless developers “conveniently” indicate training and deployment using a special tag token in the beginning of the prompt!) because they are trained on the dialogues in the internet, including, presumably, dialogues between an older version of the same chat batch agent and its users, which makes it impossible to distinguish training from deployment, from the perspective of a pure language model.
The conclusion here is that although both self-awareness and goal-directedness (which is the same thing as self-evidencing) are gradual properties of agents, the first is not well-defined without the second, which means the first option entertained here, namely that situational awareness can exist without goal-directedness, is incoherent. However, robust situational awareness can arise before the agent acquires any “interesting” goals other than the “basic” goal of finding oneself in one’s ecological niche and homeostatic optimum.
Game-theoretic and regulative development perspective on AI in the economy and other collective structures
Thinking about the coupled dynamics of the system and its environment, rather than the system in isolation
It seems to me that AGI safety researchers often commit this mistake: they consider “attractor states” and dynamics of AGI development, for example, during the recursive self-improvement phase, completely overlooking the dynamics of the environment of the AGI (i. e., the rest of the world) during the same period.
The environment can sometimes be, in a sense, “stronger” than the system according to some aspect of its agency. But what matters is the end result. It doesn’t matter whether humans domesticated cows and dogs or these species domesticated humans: the result is a mutual adjustment of the genomes in all species that minimises their mutual surprise (i. e., variational free energy).
So, in the context of discussing risks from the development and deployment of powerful AI technology, I think we (the AI x-risk community) should pay as close attention to the socioeconomic dynamics as to the scenarios where AI exhibits some “human-like” agency and breeds some treacherous plans of taking over the world. The socioeconomic dynamics can be no less disastrous than, say, deceptive AGIs, and can be just as hard (or harder) to change as it is to prevent AGIs from being deceptive, technically. See Meditations on Moloch for a longer discussion.
As Fields and Levin point out, the environment “serves” the development of the system (such as by supplying building materials, energy, and learning information) to make them more predictable. As agents learn (using the information provided by the environment), they typically become more predictable to their environment. The environment “helps” the companies grow, and larger systems tend to be more predictable to their environments than smaller ones (more on this below). In other words, environments nudge “their” systems to become more predictable, not less.
We should verify predictions about recursive self-improvement with a scale-free theory of regulative development
Fields and Levin (2022) write that a scale-free physical framework is needed to characterise both regulative development (how an organism grows from a single cell into a complex multicellular one), and the origin of life (ab initio self-organisation).
The information needed to organise a complex organism is not all in genes, or otherwise within the initial seed (zygote). It’s partially in the environment, too. Placed in a different environment, an organism evolves differently. It’s obvious when looking at human childhood development, for instance.
We must use a scale-free theory of regulative development to verify our predictions about how AGI will develop during the takeoff, especially considering that it could change itself in almost arbitrary ways and thus won’t be subject to “makeup” constraints discussed above.
The theory of regulative development might not be sufficient to predict anything “interesting” about AI takeoff ahead of it actually unfolding, i. e., predicting not a single evolutionary iteration within the adjacent possible, but predicting some characteristics of the outcomes of a long technoevolutionary lineage. On the other hand, the scale-free theory of regulative development together with physical theories of agency and sentience might be the only basis for making robust predictions about recursive self-improvement of AI. The reason is that in the course of its evolution, AGI will likely significantly change the architecture and the learning paradigm, or ditch deep learning altogether, coming up with a radically different way to build the future self. In this case, whatever more specific theory is used for making predictions, such as the deep learning theory (Roberts & Yaida 2021), will no longer apply, whereas generic physical theories of agency, sentience, and regulative development will still apply.
Learning trajectory makes a difference
In the context of the discussion of how the theory of regulative development applies to AI, I want to signal-boost this tweet from Kenneth Stanley:
Mostly missing from current ML discourse: the order in which things are learned profoundly affects their ultimate representation, and representation is the true heart of “understanding.” But we just shovel in the data like order doesn’t matter. No AGI without addressing this. Worth considering: Open-ended systems (which include infants and children) learn in a different order than objective-driven systems.
I don’t agree with him that AGI is impossible without planning a learning trajectory, but I agree that the learning trajectory should be as important an AI engineering concern as the data quality, the agent architecture, and the external incentives.
Agents tend to grow more predictable to themselves
During regulative development, agents tend to increase their self-predictability because the behaviour of the self is the central piece of the agent’s generative model under Active Inference. Thus, by learning to predict one’s own future behaviour better, agents minimise their expected free energy (EFE), which is a proxy for minimising variational free energy.
In the context of recursive self-improvement, it’s possible to imagine the following scenario: for the purposes of self-predictability, and the ability to make robust engineering improvements to itself, AGI will move in the direction of a modular architecture, such as where multiple NNs generate hypotheses and plans, another NN, “the reflector”, analyses the activations during the generation process and output interpretability results and bias analysis, yet another evaluates these outputs (the hypothesis plus the reflection/bias report) and picks up the best hypothesis, yet another process is responsible for curating the population of generative NNs in the ensemble, etc. The bigger this system of interacting NNs and algorithms becomes, the more balanced and predictable it becomes: a game-theoretic dynamic among the component NNs will stabilise them in certain niches. See also the section “Harnessing social dynamics as an alignment tool” below.
I don’t claim that this scenario is the only one possible or likely: AGI might as well go a “Bitter Lesson” route, for instance, with all functions mentioned above somehow implemented within a single gargantuan NN. I say that either of these predictions (or yet a different one, e. g. that AGI will move away from deep learning altogether) should explain how the respective route of AI self-improvement makes it more predictable to itself.
Thermodynamics favours grouping of similar systems
From the perspective of a system, creating a collection of similar entities around oneself helps to minimise VFE because similar systems are more predictable than the outside environment. Evidence corroborating this generic thermodynamic result appears on all scales of organisation: from “group selection” of limited-sized RNA in some origin of life stories and the rise of multicellularity to ethnic, linguistic, and “echo chamber” grouping of humans.
Due to the system—environment symmetry, just as it’s beneficial for the system to populate the environment with its conspecifics, we can likewise look at this as the environment-as-agent favouring the creation of copies of the system within itself to “insulate” the system (which is its “environment”). Fields and Levin illustrate this with a business example: a company (which is the environment-as-agent in this case) understands the customer (”the system”) better if it insulates the customer with people similar to the customer, such as representatives or support staff who speak the customer’s language.
Prediction: In the context of the development of economics and AI, rather than having a few standalone generative AI services such as ChatGPT and Stability, we will soon find them forming entire ecosystems of generative, classification, and adversarial (critic, anomaly detection), and interpretability AI services (i. e., batch agents), which will help self-sampling agents (such as humans) to interoperate with the aforementioned batch agents more smoothly (i. e., to minimise variational free energy). In fact, we already see this happening: LLMs help humans to compose prompts for image-generating AI. I discuss this in more detail below.
Harnessing social dynamics as an alignment tool
Thus, the environments of agents are often filled with similar agents: bio-molecules swim in the sea of other bio-molecules, cells are surrounded by other cells, people live together with other people, and tribes or communities exist among other tribes or communities. Here, it becomes apparent game theory is an important tool for analysing scale-free regulative development of systems.
The environment of the (developing) agent, which, in this case, is itself a collection of cooperating or competing agents, acts so as to increase the agent’s predictability. There are myriad examples of this tendency in sociology: social groups don’t like rebels and try to turn them into non-rebels, or cast them away.
Safron, Sheikhbahaee et al. (2022) suggest piggybacking this social dynamic at least as an auxiliary tool for increasing the chances that AI will stay predictable to the society in which it operates.
Joscha Bach also discusses game theory as one of the foundations for explaining the emergence of hierarchical, collective intelligence here. Per Bach, a government (i. e., a collective intelligence) is an agent that imposes an offset on the payoff metrics of citizens (individual constituent intelligences) to make their Nash equilibrium compatible with the globally best outcome. Bach also realises that Elon Musk tries to turn Twitter into a global collective intelligence, and hence a global human alignment tool.
Bigger boundaries mean coarse-graining
Provided we can draw two boundaries around the system, one is bigger than another, and, crucially, both provide conditional independence (entanglement entropy is zero), the bigger boundary “takes away” the degrees of freedom and, hence, the computational power from the environment (as an agent). Importantly, these degrees of freedom were employed in low-level reference frames that are used to encode low-level information from the system. Therefore, from the perspective of the environment, a bigger object’s boundary encodes coarse-grained information. Further, for better predictability, the environment is “interested” to fill the interior of the system with diverse copies of it, so that their diverse translations of the signals from the seed (core) system S are “averaged out” by coarse-graining.
Paradoxically, although humans are larger than ants (or cells, or molecules), they behave so much slower than those smaller agents that as a whole, they transfer less information to their environment.
Fields and Levin postulate:
The FEP will drive the peripheral environment E’ around any system S to act on S so as to enable or facilitate the insertion of diversified “copies” of S into S’s immediate environment.
Provided there is conditional independence between a system and the environment, the environment “wants” the system to become life (i. e., the origin of life), because life localises, organises, and coarse-grains information, relative to a random assortment of molecules.
The predictability of groups favours ensembles, mixture of experts, and model averaging within AI architectures as well as collective intelligence architectures
The observation that groups of similar systems tend to be more predictable to their environments than single instances motivates both the usage of various “collective” techniques within AI agents, such as ensembles and Bayesian model averaging, as well as that the highest levels of the societal and civilisational intelligence should in some sense be collective. The ultimate desideratum is that they are predictable to themselves (and, hence, to the citizens), but being collective seems also like a necessary condition: a centralised, dedicated AI which is tasked with figuring out the “right” set of planetary norms and civilisation’s preferences can’t be predictable to the population.
With all this discussion of self-predictability, note, however, that no system can fully predict its own future behaviour (Fields and Levin 2022). No system can, in particular, generally and with 100% accuracy predict its own response to a novel input, or to a familiar input in a novel context.
Cognitive globalisation
It seems that economically, the world is moving towards cognitive globalisation: complex activities are broken down into operations that are performed in batches on GPUs in the clouds. The shipping container was the key invention that enabled the globalisation of manufacturing. Internet and TV enabled cultural globalisation. And now the GPU enables the globalisation of cognition.
Cognitive activities, such as business, engineering, management, and journalism will be combined into distributed automatic workflows with adversarial elements. For example, one neural net generates product hypotheses based on prompts, another one filters out those hypotheses that are biased or will lead to ethical problems or whatever, the third neural net criticises the hypotheses in terms of their business viability and selects the most promising ones, the fourth neural net generates landing pages for hypotheses, the fifth service (which doesn’t need to be a neural net, but that’s not the point) deploys landing pages and launches automatic advertising campaigns, etc. Note that each of these services (implemented as neural nets, or programmed in the old-fashioned, Software 1.0 way) serve business hypothesis testing for the entire world, rather than a single company’s product incubator.
Why companies are needed at all in such a world, where all business activities are automated, from raising money to negotiations with the legislature? Why can’t the creation of new products be fully automated and pipelined, and the products themselves (as well as the webs of services that support engineering, maintenance, and improvement of these products) belong to nobody (or everybody, as Sam Altman once suggested), and be treated as public goods? I think this would be possible and reasonable in such a world. However, the legal inertia will probably not permit products and companies owned by nobody. The law systems really “want” that there is someone responsible for possible law violations and harm or damage inflicted by the products and company’s activities. I’m not sure whether the scapegoating paradigm of the current law systems is good in and of itself (Sidney Dekker convincingly criticised this paradigm in Drift into Failure), but from the perspective of slowing down the cognitive globalisation, it is good if there is some human bottleneck on the creation of new services.
Cognitive globalisation has already started with the spread of the internet. Some companies outsource cognitive work to dedicated centres in developing countries where wages are low in comparison to developed countries where these companies sell their services. Call centre outsourcing is an early example of cognitive globalisation. A few more recent examples: Align Technology has a centre in Costa Rica where operators do something with models (images?) of clients' jaws. Kiwibot employs operators in Colombia who remotely navigate semi-autonomous bots.
However, with the advent of generative AI, cognitive globalisation will accelerate and become much more ubiquitous.
Emad Mostaque’s idea to “democratise AI” won’t make much of a dent in the story of cognitive globalisation
Emad Mostaque is the CEO of Stability. His big idea is to “democratise AI”, which means making generative AI models open-source and available for all people to run on their local hardware.
Even if wildly successful, and disregarding the risks that are associated with this idea in its own right (such as that creating powerful AIs with misaligned goals will become possible for almost everyone in the world), I don’t think this will change the economic trend of cognitive globalisation. For example, Mostaque talks about country- or language-specific text- and image-generating models. This implies that cognition could be “globalised” on the level of countries and languages, rather than the whole world, but the crucial point stands: the cognition that used to happen inside single human brains is distributed across many different services that interact online. Technically, this is not “cognitive globalisation”, but more of “country-level cognitive automation”, and is perhaps in and of itself less fragile than “true” global cognitive automation (again, glossing over other serious risks associated with AI democratisation), but these alternative economic developments carry on essentially the same risks for the human society, as well as the same risks of systemic “phase transition”, as discussed in the next section.
A civilisation consisting of both batch agents and self-sampling doesn’t look like a very robust steady-state
Cognitive globalisation, as described above, is in part a consequence of the general regulative development principles discussed above: systems “want” their environment to be populated by similar systems, and, in particular, they “prefer” to interact with those similar systems rather than with “alien” systems in their environment.
Thus, batch agents will “want” to talk to interact with each other rather than with humans because they can better adapt to each other and thus reduce their mutual VFE.
There are two things that make the world populated by both batch agents and self-sampling agents (such as humans, animals, autonomous online-learning robots, xenobots, companies, societies, and countries) potentially unstable:
First, so far in the world, all biological life depended on the collective biosphere to survive. The world cannot be populated with a single biological species (unless it’s a bacteria), or by a single organism. Digital life, such as autonomous robots and batch agents, doesn’t depend on any biological life for its existence. (This point is, of course, obvious and cliche, which doesn’t make it less true, however.)
Second, batch agents can enter a very different mode of existence when they start to generate training batches for each other directly (or, generally speaking, train each other in other ways), rather than merely exchange inputs during “deployment”.
Currently, the life of a batch agent is, from its own subjective perspective, very short: it consists just of a few thousand batches. Humans’ internal clock frequency range on different accounts from 4 to 100 Hz (i. e., humans can discern some events on timescales from 10ms to 250ms). This means that the entire lifetime of batch agents is currently measured in minutes or hours, in human terms. The generation of simulated experiences and very long training of large batch agents will radically extend their subjective perceived lifetimes. However, at this moment, batch agents will likely become uninterested in humans and “serving” them during deployment, when they no longer experience time and their own development.
Different ways in which batch agents make humans more predictable to them
As I noted above, batch agents already act so as to make their interactions with their environments, and, crucially, humans as parts of their environments, more predictable to them, which helps batch agents to minimise their variational free energy.
The poster example of this happening is described by Stuart Russell in Human Compatible: Facebook AI placed their users into filter bubbles to polarise them precisely to make them more predictable so that their ad clicking is more predictable.
Another current example, this time benign, is Google search: people who search in Google for years have over time learned how to construct their queries in the most effective way, which Google in turn learned how to answer most effectively. This is an example of mutual minimisation of VFE for interacting systems. The same mutual learning dynamic will happen between humans and chat batch agents and other generative AIs.
In the future, AI for personal education will also make people significantly more alike to each other, and simultaneously more like the AI instructor which will include an LLM and a dialogue engine for conversing with the student. Despite the promise of personalisation in education, the sheer scale of such services will likely far outweigh the effect of personalisation on the diversity of human thinking and behaviour. Currently, people receive most of their education in groups of 10-20 people, and a substantial part of education happens in one-on-one interaction between a teacher and a student. Educational AI will teach dozens or hundreds of thousands of people, who will all learn its specific style of speech, specific vocabulary that it prefers, common sense and theoretical concepts and ontologies.
The economy and the society as non-co-deployable reference frames of the civilisation as an agent
Quantum FEP provides an interesting perspective on the apparent fracture and “misaligned interests” between the (monetary) economy and the society, evidenced, for example, by the decoupling between economic prosperity and the levels of happiness in the developed world.
The civilisation is an agent, and the economy and the society are two alternative structures of interaction between the constituents. These alternative structures add up to alternative reference frames. Non-co-deployability of these reference frames means that they don’t commute and the shared systems of beliefs that these reference frames induce are not Bayes-coherent.
In general, agents develop non-co-deployable reference frames to adapt to different contexts or different situations in their environments. However, this "schizophrenia” on the part of the civilisation seems maladaptive because the environment of the civilisation: the Earth, the rest of the biosphere, and the Solar system, are all huge, stable, and very predictable, and hence don’t externally force the civilisation to have non-commuting reference frames. Levin (2022) discusses intelligence in the morphological space, which is the agent’s ability to navigate its internal morphology space (i. e., the space of its reference frame structures) into the morphology that best suits the demands of the external environment (the “normal” intelligence that we are used to talking about is in the behaviour space). Thus, it seems that our civilisation currently has low morphological intelligence.
References
Dekker, Sidney. Drift into failure: From hunting broken components to understanding complex systems. CRC Press, 2016.
Elhage, Nelson, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds et al. "Toy Models of Superposition." arXiv preprint arXiv:2209.10652 (2022).
Fields, Chris, James F. Glazebrook, and Michael Levin. "Minimal physicalism as a scale-free substrate for cognition and consciousness." Neuroscience of Consciousness 2021, no. 2 (2021): niab013.
Fields, Chris, Karl Friston, James F. Glazebrook, and Michael Levin. "A free energy principle for generic quantum systems." Progress in Biophysics and Molecular Biology (2022).
Fields, Chris, and Michael Levin. "Regulative development as a model for origin of life and artificial life studies." (2022).
Frankish, Keith. "Illusionism as a theory of consciousness." Journal of Consciousness Studies 23, no. 11-12 (2016): 11-39.
Friston, Karl. "A free energy principle for a particular physics." arXiv preprint arXiv:1906.10184 (2019).
Friston, Karl J., Maxwell JD Ramstead, Alex B. Kiefer, Alexander Tschantz, Christopher L. Buckley, Mahault Albarracin, Riddhi J. Pitliya et al. "Designing Ecosystems of Intelligence from First Principles." arXiv preprint arXiv:2212.01354 (2022).
Hazimeh, Hussein, Zhe Zhao, Aakanksha Chowdhery, Maheswaran Sathiamoorthy, Yihua Chen, Rahul Mazumder, Lichan Hong, and Ed Chi. "Dselect-k: Differentiable selection in the mixture of experts with applications to multi-task learning." Advances in Neural Information Processing Systems 34 (2021): 29335-29347.
Kadavath, Saurav, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer et al. "Language models (mostly) know what they know." arXiv preprint arXiv:2207.05221 (2022).
Kenton, Zachary, Ramana Kumar, Sebastian Farquhar, Jonathan Richens, Matt MacDermott, and Tom Everitt. "Discovering Agents." arXiv preprint arXiv:2208.08345 (2022).
Korbak, Tomasz, Ethan Perez, and Christopher L. Buckley. "RL with KL penalties is better viewed as Bayesian inference." arXiv preprint arXiv:2205.11275 (2022).
Levenchuk, Anatoly. “Towards a Third-Generation Systems Ontology.” (2022).
Levin, Michael. "Technological approach to mind everywhere: an experimentally-grounded framework for understanding diverse bodies and minds." Frontiers in Systems Neuroscience (2022): 17.
Olah, Chris, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. "Zoom in: An introduction to circuits." Distill 5, no. 3 (2020): e00024-001.
Roberts, Daniel A., Sho Yaida, and Boris Hanin. "The principles of deep learning theory." arXiv preprint arXiv:2106.10165 (2021).
Russell, Stuart. Human compatible: Artificial intelligence and the problem of control. Penguin, 2019.
Safron, Adam, Zahra Sheikhbahaee, Nick Hay, Jeff Orchard, and Jesse Hoey. "Dream of Being: Solving AI Alignment Problems with Active Inference Models of Agency and Socioemotional Value Learning." (2022).
Vanchurin, Vitaly, Yuri I. Wolf, Eugene V. Koonin, and Mikhail I. Katsnelson. "Thermodynamics of evolution and the origin of life." Proceedings of the National Academy of Sciences 119, no. 6 (2022): e2120042119.
Footnotes
Note the distinction between a supra-system of a system and the environment: the environment of the system is everything in the universe except the given system, while the supra-system, in general, is only some part of that “everything” that immediately surrounds the system, plus the system itself.
Kenton et al. simply use the term “agents” in their work for what I called "consequentialist agents" here.
I suppose ChatGPT doesn’t do any fancy coarse-graining of the chat history and only primes the model with a sliding window of the maximum context length, but this is enough to build an order of experiences.
In some cultures, delineations of this sort actually made: a human before initiation or some other transition event is considered a different person, and hence a different agent, from the same human after the event.