
The personal AI platform: technical blueprint
Pocketbase and LanceDB for extensible personal AI data plane and system of record
Giving a more concrete shape to the platform part of the Personal Agents vision. The primary motivations for the Personal Agents agenda are: reduce the power imbalance between "Big Token" corps and people; and enable political and media innovation through deployment of personal "political representative" AI agents, "info agents", and the like.
Summary
The unifying abstraction between various personal AI apps and integrations should be the common models (schemas and access APIs) for personal context data: chats with AI, notes/documents, emails, tables/records, visited web pages, media feeds such as news and podcasts, and so on.
AI chats, notes, and tables live in Pocketbase.
Immutable objects: web page snapshots, emails, PDF docs, and media (podcasts, images, etc.) go to LanceDB.
LLM requests and responses (for AI app debug, LLM usage analysis/audit, and "Reasoning" collapsible expansion in AI chat UIs) and service API call logs are also stored in LanceDB.
Pocketbase connects to the personal computer to sync browsed web pages, notes and tables (e.g., from Obsidian), and personal media. Alternatively, the app running on the personal computer can act as an MCP server for the AI apps, such as Open WebUI that are also deployed privately alongside the data plane services:
Pocketbase with app-specific and user-defined JS extensions,
The search and data ingestion service that embeds LanceDB,
The LLM, MCP, and service API proxy that is based on LiteLLM and also embeds LanceDB for storing LLM (and other service API calls, such as web search, web scraping, audio transcription, media generation, etc.) requests, responses, and costs.
The personal AI platform (that includes the data plane and the AI apps that use it, such as Open WebUI) could be deployed either in a private VPS or in a cloud service such as Fly.io, where each user has a separate private org to which they can deploy custom AI apps at will.
The fact that the data plane is private, not censorable, and not owned by a big tech corp should increase people's trust and willingness to upload their personal data: browsing history, emails via IMAP from Gmail, etc.
In turn, this personal context data is very attractive for AI app developers who face the "cold start" problem: the AI app isn't very useful until it has access to the personal context. The common data model for things like chats with AI, notes/documents, e-mails, etc., makes a "warm start" possible: people can deploy the AI app privately and see how it works with their existing chats, documents, and other context. Thus, people can experiment with different AI apps without any data import/export hassle.
Many apps have chat UIs so they can leverage the common data model. Yet, the apps still can differentiate a lot in terms of their focus and specific knowledge (think financial assistant vs. psychotherapist), communication styles and agency levels ("analyst" vs. "doer"), personalisation abilities, tools such as web search or MCP used, etc.
Specialised apps such as medical or financial consultants can do vector search over all of the existing personal context across modalities (AI chats, search and browsing history) proactively while the app is executed for the first time to personalise the suggested prompts or even start working on the user's recent questions or problems right away.
The freedom of choice between different AI apps and LLMs providers, the ability to vibe code the personal system of record, and unified billing for hosting, LLM calls, and other API services should make the personal AI platform more attractive to people than limited, "one size fits none" subscription offerings from big tech corps.
This is the first post in a three-part series. In the rest of this post, I detail the reasoning behind the technical decisions that shaped this personal AI platform vision so far, concerning the personal data plane architecture for deployment simplicity, durability, and amenability to multiple AI apps coexisting on the platform. I also describe the development path to the minimum viable personal AI platform at the end of this post.
In the second post, I'll focus on the platform's privacy and security architecture. After that, I'll discuss possible PaaS providers’ and AI app developers’ business models for the personal AI platform.
The middle level in the personal AI platform's hourglass architecture: databases, data model, and query APIs
For the context on multi-level/layer architectures, see my earlier posts "Architecture theory and the hourglass model" and "AI agency architecture-in-the-large: the relevant levels of abstraction".
The idea that the "personal AI app platform" should be a data platform first and foremost seems so self-evident to me that I'm having a hard time explaining why I think so: I don't even see realistic alternatives. Cf. the proposition that I made in another recent post: that AI app developers should better "use immutable data schema/design to unify app's persistence and tracing".
Here's the obligatory hourglass diagram:
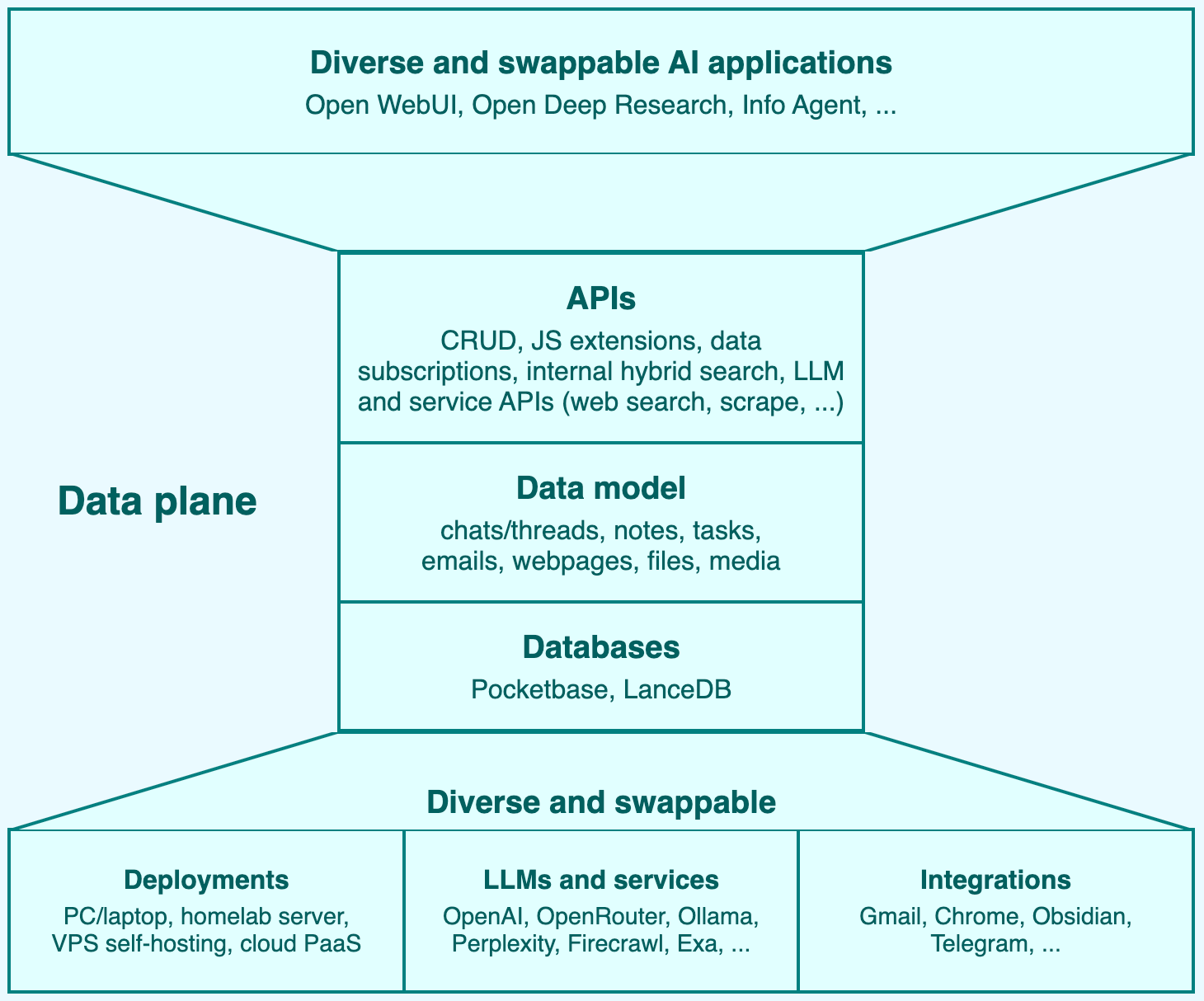
Six months ago and earlier, the vast majority of agentic frameworks were predominantly focused on the "control flow and intelligence stuff": workflow execution, workflow design, agent orchestration, tools, MCPs, and capabilities rather than persistence and data models.
Convex Agents is the only exception that comes to my mind. Other frameworks in which the persistence schema is externalised and made somewhat a public API are Letta (via the Agent File format) and Mastra (see Mastra's data schema). However, neither Letta nor Mastra supports persistence to a reactive database.
I call a database reactive if it supports real-time data subscriptions and embedding custom HTTP routes/methods and "triggers" written in a popular programming language without severe runtime constraints (to distinguish from good old SQL RDBMS triggers). Data grid, database inside out, and headless CMS are overlapping ideas.
A reactive database permits independent AI apps (written in any language and with any agentic framework, or without any framework) to interoperate around the common data model.
For example, a specialised app can produce chats with some app-specific fields, but if those chats are still stored in the common chats table, they can at least be searched over, or even picked up by another, generic chat app. This is helpful if the user has abandoned the app that produced some chats, but may still search and access those chats through other, generic AI chat apps (such as Open WebUI) that they still use.
For the above case, database reactivity per se is not necessary. However, there are plenty of use cases for personal AI-first system of record or exocortex that do require database reactivity and "micro-ETL" within the database, such as:
An LLM workflow that classifies and triages inbound emails.
A proactive personal assistant that suggests creating tasks or action items from chats and searches.
An "info agent" that processes many information feeds (news, podcasts, discussions in groups, cold inbound requests, etc.) to prepare the five most salient/attention-worthy posts or messages per day to present to the human.
Architectural goals for the personal AI platform
In the following few sections, I'm explaining why I picked Pocketbase as the personal data plane's reactive database and LanceDB as the database for searching immutable data and logging LLM and other service API calls, respectively.
Keep in mind the architectural goals for the personal AI platform that motivate these technology choices:
Simplicity of deployment: the personal AI platform must be deployable on a single host, such as a personal computer or a VPS.
Cloud-grade durability: even in a single-host setup, it should be possible to durably back up the data to object storage, and this backup itself shouldn't require complicated extra machinery. If the object storage service is separate from the VPS hosting, this safeguards the personal data even against abrupt VPS account termination and provides a high degree of resilience to deplatforming.
Privacy: the personal AI data platform should be fully functional even when the user's LLM activity doesn't exit the host (or the Fly.io org in a cloud setup), with LLM inference through Ollama or similar. It should be possible to configure the data plane such that access to the host machine's local disks doesn't leak personal data, either in self-hosted or cloud setups. So, all data on disks should be encryptable by user-owned keys.
LLM security: screen all inbound data (emails, web pages, etc.) for prompt injections by default. Post-call guardrails for all LLM calls made from the AI apps are ON by default. This explains why the platform has a separate LLM proxy service (based on LiteLLM) rather than leaving LLM routing and guardrails to AI apps.
Amenability to multiple AI apps coexisting on the platform, where these apps are developed independently and externally. This means that apps should be able to register their extensions to the reactive database dynamically, i.e., without the need to re-deploy the database. This motivates the stricter LLM security baseline: we cannot count on independent AI app developers to always consistently follow the LLM security practices.
Governability and software supply chain security: it should be possible to configure which data tables (emails, browsed web pages, notes, etc.) every deployed app has access to. It should be possible to configure manual approvals for apps' requests for data access, dynamic trigger registrations, or requests to skip LLM guardrails. Manual approvals can be skipped only if the app's container image meets certain criteria, such as: built from a public GitHub repo with provenance attestation and doesn't register new vulnerabilities (relative to the previous deployed app version) with osv-scanner.
Business-friendliness: to attract app developers and enable commercial hosting of the personal AI app platform (which is critical for the personal AI platform adoption, as self-hosting would require people managing too many separate service API and hosting subscriptions; this is discussed in more detail in ), the technologies comprising the data plane have to be open source rather than source available.
Reactive database: Pocketbase
Here are reactive databases (see my definition above) that I'm aware of:
Supabase: edge functions in JS or TS, persistence to Postgres.
Nhost: serverless functions in JS or TS, persistence to Postgres.
Convex: backend functions in JS or TS, persistence to Postgres or SQLite.
SurrealDB: embedded JS functions can be used from events, custom storage.
Rama: Java and Clojure APIs, custom storage.
RisingWave: UDFs in Python, JS, Rust, or Java, persistence to Apache Iceberg.
Pocketbase: extensions in Go or limited JS, persistence to SQLite.
Strapi: backend customisation in JS or TS, persistence to Postgres, MySQL, SQLite, ...
Directus: API extensions in JS or TS, persistence to Postgres, MySQL, SQLite, ...
Apache Ignite: Java, C#/.NET and C++ primary APIs, custom/pluggable storage.
Google's Firebase: cloud functions in JS, TS, or Python, proprietary storage.
AWS Amplify: custom functions in JS, TS, Python, Go, Java, ..., proprietary storage.
Rama, RisingWave, and Apache Ignite focus on scalable, high-performance backends, not scrappy full-stack AI apps operating with tiny amounts of data. They use custom storage engines, which would not be a very legible choice for the open data plane platform.
Supabase and Nhost only support Postgres as the persistence option, which is overkill for tiny personal AI data planes. They are also focused on scalable backends and "real" cloud deployments, not small personal backends and PaaS/scale-to-zero deployments: e.g., Nhost relies on AWS Lambda for running extension functions. Also, both Supabase and Nhost are notoriously hard to self-host.
I think the personal data plane should be based on SQLite, which should be synced to object storage for durability via Litestream.
Convex and Directus support persistence to SQLite, but are released under source available, non-OSI-approved licenses: Functional Source License (FSL) and Business Source License (BSL), respectively. This is a deal-breaker for the open personal AI platform and businesses that may want to build with it. SurrealDB also uses BSL.
Strapi is open source, but treats SQLite as a second-class, "demo usage only" persistence option.
Trailbase is not listed as a reactive database above because it doesn't support record create/update/delete triggers. It's focused on supporting the creation of a single coherent application on top of the single database, not a loose federation of interoperating apps.
Payload CMS has a permissive license. It supports SQLite (or, at least, libSQL) as a first-class persistence option alongside Postgres.
The reason why I didn't list Payload CMS as a reactive database is that it doesn't support realtime data subscriptions yet. However, this isn't an inherent architectural limitation. Also, Payload positions too much as a "Next.js framework" rather than a language-agnostic "database with HTTP APIs, auth, and other goodies" (like Supabase, Convex, and Pocketbase), which might be alienating for AI app developers who don't use JS/TS. The startup that develops Payload CMS was recently acquired by a big corporation (Figma), which is a double-edged sword.
So, by exclusion, I currently choose Pocketbase as the reactive database for the personal AI data plane. It ticks all the boxes: permissively licensed, persisted to SQLite, and has a well-thought-through extensions API. However, Pocketbase has a notable downside (for the purposes of putting it at the core of the open data plane/platform): it's not open to contributions. So is SQLite, though, but, of course, SQLite is an incomparably more proven, stable, and sustainable project, and has a much more mature ecosystem of plugins.
Overall, to my mind, this is still a relatively close call between Pocketbase and Payload CMS, so I may change the decision in the future.
Data schema with versioned objects enables extending Pocketbase with serverless code in any language
Pocketbase's runtime for dynamic JS extensions (hooks, custom routes, middleware, and migrations), goja, is rather limited: it doesn't support fetch() and async/await code.
This would be a serious downside of Pocketbase. However, the personal data plane use case permits database-managed subscriptions: triggering serverless functions, or directly the AI app that needs a database extension, without live HTTP connections for server-sent events.
Containerised extensions enabled by database-managed subscriptions are also essential for the deployment of independently developed AI apps (and/or serverless functions) against a single database so that they don't conflict on library versions required. To this end, this system design would also be necessary with any other reactive database, even those that include V8 JS/TS runtimes, like Convex or Trailbase. All these reactive databases were designed to be a backend for a single app, not an unknown federation of apps.
Database-managed subscriptions are possible to implement on top of Pocketbase due to the following characteristics of the target use case, i.e., the personal context data plane:
The common data model should anyway keep the version history of mutable objects: messages and results in AI chats (the user can edit their own or AI messages or re-run the AI turn), the chat itself (the user can drop turns or insert new messages), notes/documents, table records, etc.
These version histories will generally be very short. The only exception is documents that may have thousands of versions if the app saves the document to the database every few seconds, but for AI app interoperation, document updates can promptly be rolled up to 15-minute or longer intervals: there is no realistic use case for AI apps to eavesdrop on document updates with higher granularity.
The total number of versioned objects is small (thousands or tens of thousands at most?), and the cumulative object update frequency (~1 update per second at most) is tiny by the standards of what SQLite is capable of processing in terms of data volume and transactions per second.
The total number of subscribers (AI apps and serverless functions) is a few dozen at most.
Interoperation across AI apps through the personal data plane shouldn't be formally correct and precise: these are just personal AI apps, not high-stakes financial transactions. AI apps’ interactions will at most be something like background context enrichment, fine-tuning, or perhaps kicking off some optional research workflow on behalf of the user. So, trigger extensions for AI app interoperability don't need to propagate transactions correctly through the unified "versioned database" graph. Concretely speaking: if one app updated two or more objects within a single transaction (e.g., the message within the chat and the chat itself), another app that subscribes to these updates should be fine if it receives these two updates independently, in any order, or receives one and doesn't receive another because it gets reverted or overwritten quickly, or, in rare cases, misses updates altogether.
The actual implementation of database-managed subscriptions could be as follows: a database-managed subscription is created an API request with the same parameters as realtime subscriptions, plus the target address, path, and extra parameters for PUT requests that the subscription should produce. Each subscription creates a separate table in SQLite to store the object versions that are not yet consumed by the target serverless code or app. This table acts as a subscription queue (with deduplication). Upon each update to the subscribed object collections, the obsoleted versions of the updated object(s) are removed from the subscription queues. Object versions older than a month are also deleted (not just from the subscription queues but from SQLite altogether).
Each subscription is processed on the Pocketbase side by a dedicated goroutine that makes PUT requests to the target sequentially. Any non-error HTTP response from the target is considered a successful "consumption" of the subscription event, and it's removed from the queue. Any error cases exponential backoff before the next attempt: 5 seconds, 1 minute, 15 minutes, etc. The failing subscription means that the target app is broken or the user has shut it down. Failing subscriptions are displayed in Pocketbase's admin dashboard UI and can be removed altogether. Then the SQLite table that acts as the subscription queue is dropped. Subscriptions are automatically removed after a month of failing.
This is a very "native" and inefficient queue/stream processing solution compared to Kafka, RabbitMQ, etc., but I'm pretty sure it will work fine for personal data planes, where the expected data volumes are so low (as noted above). The advantage, of course, is that there are zero extra systems to run and manage, particularly with regard to the durability of subscription queues. Whereas when both the "main" data collections (tables) and supporting subscription queue tables are persisted in the same SQLite, there is a single mechanism that takes care of their durability, Litestream.
Other Pocketbase plugins required
Apart from database-managed subscriptions, as described above, other additions to Pocketbase are needed to make it the engine for the personal context data plane.
Database-managed JS extensions
JS extensions should be managed in SQLite and exposed via HTTP APIs rather than uploaded to the server disk. It's needed for the data plane security and privacy (more on that in the following post in this series), as well as for manageability and for the support of uncoordinated deploys of different apps. For example, the JS extension should be "owned" by the AI app that submitted it, and only that AI app and the superuser (root/admin) can update or delete the extension. See more details in the issue.
Full-text and vector search over objects
Full-text and vector indexing plugins are needed to enable searching among the latest versions of the objects: messages, chats, documents, table records, etc. Rody Davis has built the prototypes for both these plugins (see his pocketbase-plugins project) using SQLite's built-in fts5 module for full-text search and sqlite-vec for vector indexing.
I think it's better to use SQLite modules rather than bleve or embedded LanceDB with local-disk storage because fts5's and sqlite-vec's on-disk indexes are automatically encrypted if the whole SQLite is encrypted (via SQLCipher, discussed in the following post in this series). Similarly, these indexes piggyback on the main SQLite's backup to object storage. These are the same arguments that motivate building subscription queues on top of SQLite rather than with separate specialised systems.
Another option is to ingest versioned objects (chats, messages, notes) into the same LanceDB instance that stores immutable objects, see details below. The main downside of this approach is that it would make the Pocketbase instance less self-sufficient for simplified data plane setups without LanceDB. Also, this makes search indexes for versioned objects unavailable for extension JS routes and hooks.
On the other hand, with the LanceDB approach, the search APIs over versioned and immutable objects would be unified. Also, if the data plane has many thousands of messages across chats, the fact that sqlite-vec does full scans to find the nearest vectors may add too much CPU demands for the Pocketbase deployment and will require running it in more expensive VMs in a Fly.io setup to maintain acceptable latency.
So, I haven't decided yet between these two approaches (fts5 and sqlite-vec vs. LanceDB) for search over versioned objects: both approaches have pros and cons that seem commensurate to me.
Metrics
Another table-stakes addition to Pocketbase is exposing the Prometheus-style /metrics endpoint for Pocketbase monitoring (to be collected by the bring-your-own metrics store: see discussion below), as already implemented in magooney-loon's pb-ext project.
The common data schema: to be determined
I haven't yet worked on the specific details of the data schema for chats/threads, messages, and notes/documents. Probably they will be the least common denominator of:
Open WebUI's data schema: see messages, chats, prompts, notes, and tools models.
Dify's schemas are expressed in their REST APIs: see conversation history messages and document detail. I don't think Dify will actually be one of the supported apps (it is targeted more at organisational use cases and requires Postgres for storage), but the schema itself is battle-tested and therefore is worth close attention.
LangChain v1: standard content blocks in messages.
Letta's Agent File schema: messages, tools, memory blocks, agents, etc.
Mastra's data schema: messages, threads, resources, etc.
Convex Agents' schema: messages, threads, memories, files, etc.
Except, none of these schemas explicitly version objects (chats, messages, or memories/notes/documents), and only Convex Agents' objects are implicitly versioned (as everything in Convex's tables) and recoverable via the standalone TableHistory component.
I still ardently believe that mutable objects in the common data model have to be versioned, and these versions should even be exposed to the user in most chat AI apps, as ChatGPT does (see the "3/3" with arrow buttons):

But since few developers of open source AI apps currently appear to think the same, the common data schema (expressed in a set of Pocketbase's HTTP APIs and JS hook APIs) should provide the "simplified" view, such as GET /api/collections/[messages|chats|notes]/record/{id} route for getting the latest version of the object, PATCH /api/collections/[messages|chats|notes]/record/{id} route for making a new version of an object, and OnVersionedRecordUpdate() hook API. The ability to create versioned collections (in addition to Pocketbase's Base, View, and Auth collections) should itself be implemented in a separate Pocketbase plugin, perhaps.
Every application can add app-specific fields to one of the common schemas (e.g., chats/threads or notes) through a custom migration. If these fields are critical for this application's functionality or presentation, the app should register a custom route that filters the corresponding Pocketbase collection for the presence of these fields, and use this route from the app's "list" or the "entry point" view (e.g., the list of chats or the list of notes) so that when the user opens this app and clicks on one of these chats or notes, the app can work with them.
The common schemas will also have "createdBy" fields that store the name of the app that created the given object (the app name will be available as requestInfo.authRecord.id; Pocketbase will authenticate apps, not the "end users"; more on the auth architecture in the following post in this series), so the app could also just filter the collection on the objects that it created.
Currently, I don't think that there should be a common schema for "workflows" or "agent traces" (despite they are defined by multiple schema sources listed above under various names): I think they are too varied among different agentic frameworks and specific AI apps to be interoperable and usefully "listenable" (via JS hooks or database-managed subscriptions) by different apps. However, as the apps store these workflows and agent traces using their bespoke schemas in Pocketbase, they should enable full text and vector indexing of the contents of these workflows to make them "broad-base searchable" from other AI apps.
AGENTS.md equivalent for the personal data plane?
An interesting concept and a good candidate for being a part of the common data schema or convention that currently appears to be missing from all of the schemas above would be an equivalent of AGENTS.md, but for the personal context data plane rather than for coding agents. It's not exactly a Prompt from Open WebUI because prompts are specific to particular tasks and apps, while the "personal data plane's AGENTS.md" should be a more general "system" instruction for agents, instructing them how to work with this data plane, similar to how AGENTS.md is not a prompt either. A part of this instruction, which may be specific to each app, should be the list of Pocketbase collections that this AI app has access to and how they are used.
Hybrid search over immutable objects: LanceDB
Searching over a subset (or all) of digital artifacts that the person has encountered or received, including their emails, file uploads via AI (chat) apps such as Open WebUI, visited web pages (either by the person or by AI agents on their behalf), transcripts of watched YouTube videos, personal meetings, and podcasts, RSS/media items/news, etc. should be a core capability of the personal data plane available to AI apps via HTTP API since almost all AI apps require search.
First, I want to note why a separate search DB is need at all and SQLite's fts5 and sqlite-vec extensions that are proposed to be used for indexing versioned objects (chats, messages, notes) couldn't be used to index and search over immutable objects (emails, webpages, transcripts, files, media) as well: sqlite-vec may be sufficient to search over a few thousands of messages and chats (although this isn't yet clear to me without benchmarking), but its full scan vector search will definitely be too inefficient when/if there are two orders of magnitude more objects: the person may have only a few chats with AI per day on average, but the personal "Info Agent" or the personal AI assistant may easily ingest hundreds of media items and emails per day.
Of the dozens of vector and search stores, only two seem mostly compatible with the architectural goals for the personal AI platform and the data plane: (1) the simplicity of deployment both in a VPS (or locally) and in a scale-to-zero cloud PaaS like Fly.io, and (2) a straightforward way to backup the data durably in object storage: Chroma and LanceDB:
Chroma uses SQLite for WAL, and this SQLite instance could be backed up to object storage using Litestream, in the same way as Pocketbase's SQLite. (Although nobody appears to have tried to do this yet.)
LanceDB OSS supports object storage as the primary storage backend.
However, Chroma doesn't support hybrid search with BM25 yet and has to run as a standalone process. On the other hand, LanceDB could be embedded in the Python process that also implements data ingestion and checks the search permissions: see below in this section.
The biggest drawback of LanceDB OSS, it seems, is that when configured with object storage, it can't also use local disk for caching, which may increase the search query latency and the object storage egress. The "cold" search latency in a scale-to-zero cloud setup in Fly.io would probably never be smaller than ~0.7..1s to the AI app (not to the user, as the AI app may further post-process the search results with LLMs): a few hundred ms for resuming the Fly.io machine from suspended state, a few hundred ms for fetching Lance files from object storage, and some time for actual search query processing, and Fly Proxy round-trip latency. But that seems like an acceptable tradeoff. Chroma's lack of hybrid search seems like a more significant limitation, so I chose LanceDB as the search database for immutable objects in the personal data plane.
Data ingestion into LanceDB should be mediated through the Pocketbase instance. This is needed both to permit additional "micro-ETL" workflows submitted by the AI apps as hooks over these data feeds. Additionally, there should be default workflows that scan the inbound data for prompt injections to quarantine or sanitise it automatically (see more on the security architecture in the following post in this series). Finally, Pocketbase batches inbound data and inserts it in LanceDB once every 15 minutes or so to prevent LanceDB to be up too much of the time in a scale-to-zero cloud deployment, assuming it's unreasonable to set LanceDB instance's suspend wait timeout shorter than 60 seconds, given "agentic search" use cases like "search, then process results with an LLM, which emits another search tool call, repeat".
Document chunking algorithms, embedding approaches (fixed, matryoshka, or multi-vector for late interaction), embedding aggregation and hierarchical retrieval algorithms (like RAPTOR or Gwern's hierarchical embeddings for text search) are all undecided for now. The data plane should provide sane defaults for different data formats: plaintext, HTML, Markdown, and PDF.
Since no single set of algorithms can work equally well for all kinds of data, the above algorithms should be configurable per specific table (emails, webpages, transcripts, media) and/or per specific feed. The most practical way to implement this, it seems to me, is to wrap the LanceDB instance in a thin Python server that implements these pre-configured algorithms, and permit configuring the algorithms in a dedicated system table in Pocketbase.
The Python API layer also enforces table and column access permissions for the AI app that makes the search request, by consulting Pocketbase, while the LanceDB library does the actual search. (The app authenticates itself to the Python server with a dedicated key generated when the auth record for the app is created in Pocketbase; more on the auth and security architecture in a later post in this series.)
Custom, app-specific algorithms could also be supported without altering the LanceDB+Python server container image via database-managed subscriptions (see above) that send the data batches to the AI app, which uses Lance API to merge-insert their custom column values (custom embeddings, custom metadata, etc.) to records in the common tables: emails, webpages, etc.
GraphRAG-Bench paper shows that sophisticated, graph-based retrieval approaches (GraphRAG, HippoRAG, LightRAG, etc.) are more effective than "simple" embedding-based retrieval for queries against dense knowledge sets, such as technical documentation or medical instructions. The data that is supposed to be stored in the personal data plane's LanceDB (emails, webpages, and documents) is not dense knowledge sense. Hence, I don't see a point in supporting anything resembling GraphRAG in the personal AI data plane. Incidentally, this means that a graph database is not needed, which is a huge relief because it would significantly increase the overall system's complexity.
LLM, MCP, and service API proxy: a Python service with LiteLLM
The need for a standalone LLM proxy/gateway in the personal AI platform stems from the LLM security and governability requirements: see "Architectural goals for the personal AI platform" above.
Guardrails should be turned on by default for AI apps' LLM calls. AI apps should be able to submit to the Pocketbase their "recommended" settings, where they specify for which types of requests guardrails are unnecessary (e.g., because these are simple intent classification or "routing" requests) and which tools should be available (a la MCP gateway). Similar to the search access controls and chunking+embedding algorithm settings (see the previous section), the person can review these settings in the Pocketbase dashboard and track changes across the different deployed versions of the given AI app.
Apart from LLM security considerations, another reason to make LLM calls through a centralised proxy is to log LLM responses consistently across AI apps and consistently record LLM and other service API costs for spend analysis: see the following section.
In self-hosted setups, it's possible to restrict the app container's access to the internet by placing the container only on an internal network in Docker Compose and letting inbound HTTPS requests through a nginx or Caddy reverse proxy container and the outgoing requests through the LLM proxy container. In the Fly.io cloud, it should be possible to achieve similar isolation with Fly machine Network Policies that deny all egress except for the internal (Fly Proxy) traffic, so access to the proxy service, the Pocketbase instance, and the search service is still permitted.
There are surprisingly few open-source standalone HTTP proxy (gateways) for LLM calls: LiteLLM, Portkey AI gateway, and MLFlow AI gateway, maybe? And of these, only LIteLLM supports cost calculation. Also, LiteLLM has at least an order of magnitude more activity on GitHub: bug fixes for obscure combinations of providers, APIs, and features like reasoning, streaming, tool calling, structured outputs, etc., new providers added, and cost map updates. So, despite my gripes with LiteLLM's code and that LiteLLM is presumably the slowest of the popular AI gateways (which probably doesn't matter for the personal AI platform because it will generate very modest LLM call throughput), LiteLLM doesn't have serious alternatives, in my view.
If the AI apps don't have open internet access, they must proxy all their external service API calls, such as web search, web scraping, audio transcription, media generation, etc. LiteLLM supports this through custom pass-through endpoints. Similar to the guardrails, tools, and LLM model access configurations, the AI apps should submit requests to use a certain API via an HTTP request to Pocketbase, and the proxy service verifies the app's permission to access a certain API service at runtime.
Unfortunately, LiteLLM's own proxy server couldn't be used unmodified because it uses PostgreSQL and LiteLLM developers don't plan to support even vanilla SQLite, let alone Pocketbase. However, the personal data plane's LLM and service API proxy should support only a subset of LiteLLM proxy server's features and hence only a subset of their database schema, so I think that maintaining a fork of LiteLLM proxy server that uses Pocketbase instead of PostgreSQL should be manageable, despite generating a steady stream of maintenance work.
LLM and other service API call logging: LanceDB
LLM calls and other service API calls such as web search, audio transcription, translation, etc., should be logged for AI app debugging, API spend analysis, security audit, and broad-based search by other AI apps, e.g., a "system admin" AI agent that lives on the personal AI platform itself and helps the user with other app updates and debugging.
In "Connecting the semantic data traces with LLM responses", I advocated for VictoriaLogs because of its operational and configuration efficiency. Object storage backend for "cold" logs (e.g., older than a day) is a work in progress for VictoriaLogs.
However, since the data plane already uses LanceDB for search over immutable media objects anyway, it would be even simpler than VictoriaLogs to also use LanceDB for LLM and service API call logs as well.
LanceDB could be embedded in the Python proxy and used for data insertions only. Since this would be the "same" LanceDB as is used in the search service, logs could be queried and searched through the search service. Such separation is helpful for scale-to-zero deployments in Fly.io because the proxy service (Fly machine) could still have relatively little memory (500MB to 1GB) while the search service needs to have more more memory (probably, 2GB) but is called less frequently than the LLM and service API proxy and therefore is suspended for more time in total when it doesn't accrue the hosting cost.
LanceDB's upcoming JSON support will be handy for LLM request/response querying and analysis.
The LLM call log schema could be somewhere in between LiteLLM_SpendLogs and
OpenTelemetry's gen_ai_attributes schemas.
Metrics store: bring your own
As an alternative for LanceDB for LLM request/response log storage, I've considered OpenObserve that could have been used for storing LLM call logs and the various personal AI platform metrics, reported by the data plane services and the AI apps themselves. However, I decided that this is unnecessary to make the metrics store a part of the data platform. In self-hosted and homelab deployments, there is almost definitely some metrics store deployed apart from the personal AI platform, such as VictoriaMetrics, Prometheus, or ClickHouse (via SigNoz or a similar observability app). In Fly.io, there is a hosted metrics store as well.
The personal AI platform's metrics are not strictly required to be durable (unlike LLM and service API call logs), so they don't have to be synced to object storage. Using OpenObserve, a metrics store that uses object storage as the primary data storage, would incur unnecessary object storage write (ingress) amplification. Also, OpenObserve would have to be a separate service in Fly.io deployments, which would cost some extra for the users, whereas Fly.io's built-in metrics store is included in the platform cost.
The minimum viable personal AI platform: Open WebUI, browsing history, and email search
Despite paying most attention in the personal data plane architecture to the aspects of independent AI apps coexisting on the same platform and how the apps and the user can benefit from that, a much simpler and faster path "break even value" for the platform is simply making the AI apps and integrations meet: AI apps begin become more useful when they have access to the personal data that is ingested to the personal data plane through integrations. This will motivate people to use the given AI app on top of the personal AI platform (Pocketbase and LanceDB) rather than their "default" databases.
My immediate plan for making an MVP of the personal AI platform is:
Implement Pocketbase storage for Open WebUI, without any data remodelling yet. Currently, Open WebUI supports PostgreSQL or SQLite storage through SQLAlchemy, so the code is already somewhat accustomed to pluggable storage. Also, this should be relatively simple to do because Open WebUI basically doesn't do transactions, so all its database operations can translate into separate CRUD HTTP calls to Pocketbase.
Implement an MVP version of the search service based on LanceDB with one particular document chunking and embedding approach.
Make a Pocketbase plugin that reads emails from Gmail via IMAP, using go-imap, probably, and pushes the emails to the search service.
Create a Chrome plugin similar to full-text-tabs-forever that reads all pages that the person visited on desktop Chrome or another Chromium-based browser and pushes them to Pocketbase, which will in turn push them to the search service.
Add a "personal data search" tool to Open WebUI to ground AI chats with search in personal email, newsletters, and browsing history.
The OpenClaw architecture took off, not just OpenClaw itself but numerous copycats. In it, the narrow layer is not the data/data APIs, but the "agentskills.io compatible agent shape". "Apps" are not many: there is a single app, the agent itself. What is swappable is skills, plugins, and UIs/IO surfaces, like telegram, WhatsApp, etc. As well as LLM APIs / subscriptions like ChatGPT/Codex (but not Claude Code which actively fights such subscription usage).
I don't see any point in "fighting" this architecture since it already took off. For me, this is positive development, as it fulfils my vision for "Personal agents": https://engineeringideas.substack.com/p/personal-agents . I'm optimistic about the security deficiencies of current OpenClaw architecture such as susceptibility to prompt injections to be overcome over time.
In my view, currently the critical step is actually developing AI-native sensemaking skills/capabilities and new institutions which I was talking about in "Personal agents". This looks harder than I originally thought. https://www.full-stack-alignment.ai/paper and https://cosmosinstitute.substack.com/p/coasean-bargaining-at-scale is recent related work, but all such writing (including mine) remain conspicuously theoretical, "let's build this awesome stuff" instead of actually building it and, equally importantly, people then actually using it in serious contexts, cf. https://notes.andymatuschak.org/z51q8prEJzs5Jqa5WPThYoV ! This worries me.
The hourglass architecture framing is clever. Data as the unifying layer rather than the orchestration framework makes a lot of sense, especially for the personal AI use case where you want to swap between apps without losing your history.
You mention LiteLLM as the LLM proxy layer. If you're working with Claude Code specifically, claudish solves a similar routing problem. It sits between Claude Code and whatever provider you want, translating API calls on the fly. I covered it in detail here https://reading.sh/claude-code-how-to-run-any-model-gpt-5x-gemini-3-1-stealth-inside-it-e67e957e53c3
Curious what your experience has been with Pocketbase at scale. I've been eyeing it for a side project but haven't pulled the trigger yet.