


Table transfer protocols: improved Arrow Flight and alternative to Iceberg
This article is the ultimate one in the five-piece series:
1. “The future of OLAP table storage is not Iceberg” argues for why object storage-based open table formats: Apache Iceberg, Apache Hudi, and Delta Lake, although they may completely cover all analytical querying needs for some data teams, impose several significant limitations and inefficiencies for some OLAP use cases, and therefore shouldn’t be trumpeted as the “future” of columnar table storage.
2. “Proposal: generic streaming protocol for columnar data” proposes a low-level, reactive/asynchronous streaming protocol for data in Arrow or another columnar container format. The proposed protocol occupies the same niche as Arrow Dissociated IPC, but is more general and flexible.
3. “Table transfer protocols for universal access to OLAP databases” describes the M × N interoperability problem between OLAP databases and processing engines which have both greatly diversified in recent years. I discuss the existing solutions to this problem, including the usage of aforementioned open table formats, BigQuery Storage APIs, and Arrow Flight, and describe the limitations of each of these solutions that are too significant to ignore.
Then I propose a new family of table transfer protocols: Table Read, Table Write, and Table Replication protocols. These protocols are layered on the streaming protocol for columnar data proposed in the previous article. These don’t have the limitations of the other solutions to the interoperability problem between OLAP databases and processing engines.
Finally, in that article, I describe Table Read protocol in detail.
4. “Table Write protocol for interop between diverse OLAP databases and processing engines” describes Table Write protocol: a pull-based data ingestion protocol that uses Table Read protocol in reverse: the target database reads the records to write from the writing source, such as a processing engine.
This design is agnostic to transaction, isolation, and write atomicity semantics that the target database uses, but is conducive to ensuring exactly once delivery guarantees on the higher level of abstraction (the transaction or ingestion task management).
Another byproduct of making Table Write protocol based on Table Read protocol is getting an “almost free” distributed table replication method (protocol) from any OLAP database that implements Table Read protocol and into any database that implements the target side of Table Write protocol.
5. “Overview of table transfer protocols” (this post) summarises the most important points from the previous posts. For reference, I’ll generously link to the most relevant sections of the preceding posts in this series throughout the text below.
How table transfer protocols are different from Arrow Flight
Table Read protocol
Unlike Arrow Flight, Table Read protocol affords fine-grained control of
load distribution both on the server (database) and client (processing engine) sides,
resource usage on the server (database) side, enabling database nodes to serve table data for the processing engine concurrently with other real-time queries or data ingestion, and
network traffic between the server and client sides. Network traffic size could be traded off with resource usage on the database side.
Also, Table Read protocol affords consistent reads and resilience in the face of server or client node failures or table data rebalancing/redistribution concurrent with long-running Read jobs (i.e., Table Read protocol interactions).
These properties are achieved in cooperation between the server and client sides of the Read jobs.
Arrow Flight doesn’t afford cooperation between the protocol interaction sides to achieve these properties. If the client accesses the database via Arrow Flight, the database may only take singular responsibility for consistency, resiliency, and load distribution, but this is more complicated and less efficient: cooperative mechanisms for consistency and resiliency are simpler. Therefore, Table Read protocol requires less end-to-end implementation complexity to get consistent reads and resiliency than Arrow Flight.
Table Read protocol also strives to be maximally agnostic about the architectures of both databases and processing engines that could implement it, while enabling optimal read performance between any pairings of the Read job sides. Table Read protocol is supposed to work approximately equally well for
Single-node or distributed servers or clients,
Disk-first, object storage-first, or other approaches to table data storage,
Various approaches to metadata storage,
CPU-only, GPU-only, or mixed processing,
IO-bound or compute-bound query patterns, thanks to flexible network traffic control (see above), and the option to push-down processing to storage nodes.
Table Read protocol is also agnostic about the consistency/isolation model of the database.
Table Write protocol
Unlike Arrow Flight’s bulk ingestion path, Table Write protocol supports distribution on both the writing source and target database’s sides in virtue of being essentially Table Read protocol with server and client sides flipped, with only a few non-trivial additions, primarily needed to support handling the total size of written records exceeding the memory allocated to the Write job on processing engine’s worker nodes, and thus enabling query processing and ML frameworks with strong preference for memory-only operation (such as Bodo, cuDF, Dask, Apache DataFusion, DuckDB/MotherDuck, oneDAL, Polars, Ray, Theseus, and others) to effectively use table transfer protocol in the “ETL loop” with the database.
Table Write protocol is designed specifically for processing engines as the source sides in Write jobs (i.e., Table Write protocol interactions). Processing engines that typically provide consistent-at-the-offset reads to enable end-to-end exactly once delivery/ingestion guarantees for the data that “flows” through them. Table Write protocol exposes at-the-offset reading semantics (instead of hiding them behind the veneer of “simpler” abstractions) to “plug into” the exactly once delivery flow that may include a Write job at the end or as an intermediate data exchange between different systems.
Not coincidentally, the consumption of a shared log (such as Kafka) is also the industry standard for resilient ingestion in distributed OLAP databases. However, since processing engines provide consistent-at-the-offset reads like a shared log themselves, there is no need to stick a Kafka topic between sources and targets (databases) in Table Write protocol.
Scope
Table transfer protocols are lower-level than Arrow Flight SQL. I intentionally leave out of the scope of table transfer protocols:
Data access or writing permissions. This concern is left, for example, to data governance systems like Unity Catalog.
Transactions. They are left, for example, to the database layer if there is only one database system used through the processing pipeline, or to ETL/ETL tools (such as dbt) or distributed transaction systems (such as Apache Seata or Temporal) when there are more than one database, queue, or source/sink service involved in the pipeline.
Table creation, management and configuration of perpetual ingestion jobs/streams (a-la DDL). This logic is left to the target databases. However, insert, update, upsert, delete, and partition-specific semantics (a-la DML) could be specified for record writing/ingestion in Table Write protocol.
The query syntax and semantics, such as SQL. At the moment, I think it’s a good idea for table transfer protocols to embrace Substrait as the only format for expressing queries, partition breakdown of table data, schema of the written records, and negotiation of the processing logic push-back from the server to the client side. Substrait plans can be extended in many ways and at different places, which should be flexible enough to support time-travel semantics in feature stores such as Hopsworks, Chronon, and others.
While table transfer protocols are lower-level than Arrow Flight SQL, they are higher-level than Arrow Flight RPC. Arrow Flight RPC is oblivious to table-level processing logic such as projections, filtering, aggregations, table read consistency, and table data partitioning:
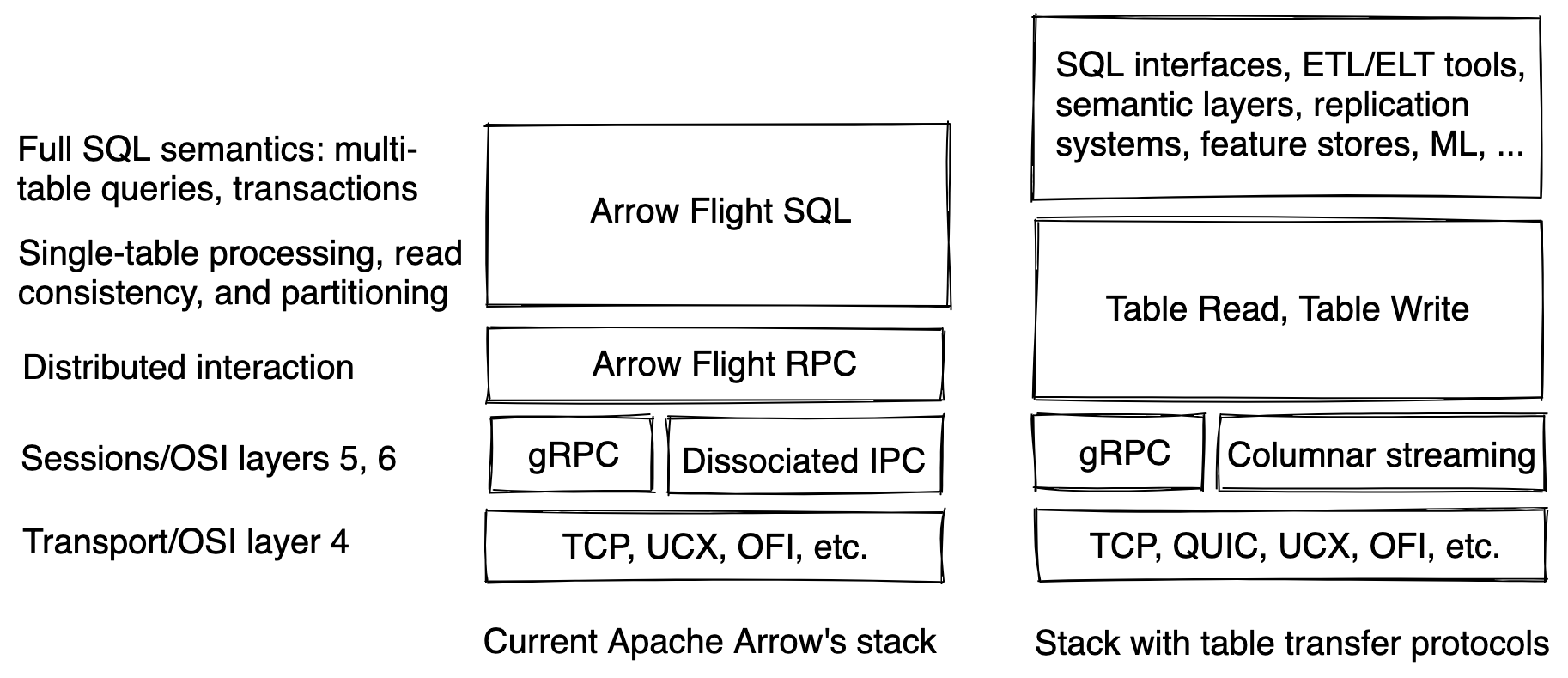
Thus, table transfer protocols are designed to be always used by other data tools and systems: SQL querying layers, transaction managers, processing pipeline planners and orchestrators, semantic layers, ML training, inference, or data science frameworks, feature stores, CDC or table replication systems, etc.
Sometimes, though not always, processing engines and databases that take part in the specific table transfer protocol interaction would also play the role of these data tools, such as when the database is its own SQL querying layer, semantic layer, and transaction manager, the processing engine is also an ML framework, etc.
Regardless, table transfer protocols also permit pulling these functions away from the storage and processing layers in line with the “database disassembly” trend.
Complicatedness
Table transfer protocols are more complicated than Arrow Flight: table transfer protocols define more node roles, request and response types, states the interacting nodes could be in, etc.
I believe that most of this complexity is essential for table transfer protocols to provide
Cooperability between the client and server sides,
Universality wrt. database and processing engine architectures, features, and semantic models,
Flexibility for efficient support of different query types, workload patterns, and heterogeneous compute hardware, and
Composability with higher-level systems and functions.
In particular, as I already mentioned above, cooperative mechanisms to achieve consistent reads, “exactly once” delivery guarantees, resilience, and optimal load distribution are usually simpler than those where only one side of the protocol interaction (usually the database) tries to take full responsibility of achieving these properties, as implied by Arrow Flight.
Note that all the attractive properties of table transfer protocols come just from making these protocols lower level and more tweakable than Arrow Flight, rather than from using some clever or novel techniques and distributed algorithms.
Moreover, achieving some of these nice properties with Arrow Flight may be just impossible by the database unless it has a certain distributed architecture, such as reverse proxy (“frontend”) nodes on the read path for availability and resilience, or a shared log on the write path for “exactly once” delivery. Sure, some databases, such as data warehouse offerings from public clouds have these elements in their distributed architectures. But most OLAP and time-series databases (and especially their open-source/on-premise tiers1) don’t have these elements. Thus, Table transfer protocols enable building resilient and consistent distributed data stacks without obligatory DBaaS and PaaS subscriptions, possibly outside the cloud.
As I noted above, table transfer protocols are designed to be implemented and directly used by database, data processing, and other data tool engineers rather than by data engineers who combine these systems for their data stacks. This fact also makes me think the complicatedness of table transfer protocols is the right tradeoff. For example, the PostgreSQL wire protocol is also very complicated, as it essentially has to be, to provide its functionality. Still, many OLAP databases adopt this protocol because it enables plugging into the PostgreSQL ecosystem.
With all that said, I also shared some thoughts about how table transfer protocols could be made less burdensome to implement by the databases and processing engines here and here. I also don’t claim that I already came up with the simplest possible designs for the streaming protocol for columnar data and table transfer protocols. I welcome your feedback and ideas about their designs!
Table transfer protocols enable the benefits of Iceberg without its limitations
Object storage-based open table formats for data lakehouse architecture: Iceberg, Hudi, and Delta Lake radically solve the interoperability problem between databases and processing engines by removing the database layer from the data stack entirely: data is ingested into and queried from the object storage directly by diverse processing engines. The interface is not as much the object storage API/protocol as the format of the files.
It’s important to disambiguate the pros and cons of using object storage as the data storage service in the lakehouse architecture from the pros and cons of using open table formats such as Iceberg per se.
There are other object storage-only (or object storage-first) databases such as Databend, Firebolt, GreptimeDB, LanceDB, OpenObserve, Oxla, Snowflake, Quickwit, and others who do not use any of the “big three” open table formats (Iceberg, Hudi, Delta Lake) yet share the benefits and limitations of using cloud object storage as the primary data storage service with open table formats.
Object storage
The benefits of cloud object storage for analytical, search, and vector querying are primarily the low cost of “cold” storage that is never or very rarely accessed, and the very high aggregate read throughput for very IO-intensive queries.
The limitations of object storage for analytical, search, and vector querying are:
Object storage-imposed read amplification and network overheads of random file access make certain analytical indexes ineffective.
The “small file problem”: high overhead of small files (and file writing as such) that prevents storing very fresh data in object storage or greatly increases the cost of doing this.
Modern databases avoid these limitations by having a layer of nodes for caching and updating recent table data, metadata, and indexes in memory or on SSDs.
At the same time, these databases can retain both main benefits of using object storage (low cost for rarely used data and high read throughput) by either making this layer completely ephemeral (like Databend, DuckDB/MotherDuck, Firebolt, LanceDB, Redshift, Snowflake, and others do), or by aggressively tiering table data to object storage, like ClickHouse, Doris, Druid, Pinot, SingleStore, StarRocks, and others could be configured to do.
Table transfer protocols (as well as Arrow Flight) can leverage this caching layer because they are just network protocols that databases can implement. However, accessing the data lake through Iceberg or another open table format is poised to miss the freshly ingested data or be ineffective for certain queries that greatly benefit from specialised indexes.
Table formats
Open table formats embody an ambitious and technically impressive idea of removing the database from the data stack by carefully re-implementing its critical functions, namely the management of table schemas, metadata, and transactions, within the so-called catalog component separated from processing engines that do the meat of ETL and query processing.
However, it seems to me that there are some not-technical downsides to the wide adoption of this idea.
Innovation speed and file format inertia
If Iceberg “wins” analytical data stack deployments decisively, it will put the entire industry in an unusual situation when the innovation in table storage formats and performance hinges on a committee design process of on-disk file formats.
This sounds like a recipe for slow progress at first and a legacy drug and “data format inertia” later.
Compliant Iceberg readers (processing engines) should already be able to read Avro, ORC, and Parquet. But these formats are not the last word in the history of columnar file formats: see Nimble, Lance, DeepLake Data Format, BtrBlocks, and Vortex, not to mention the steadily improved internal file formats of ClickHouse, Databend, Doris, Druid, Pinot, StarRocks, and other databases. Iceberg will always face the trade-off of adding new formats for efficiency vs. imposing more implementation burden forever for processing engines.
Because table transfer protocols always assume some compute on the database side, they demand that the database side at least always supports column data transfer in Arrow format, potentially in addition to other, more specialised or optimised formats. (Obviously, this is also the main idea of Arrow Flight. However, table transfer protocols don’t limit themselves to the Arrow format.)
Vendor competition and the “lowest common denominator” effect
There are a lot of OLAP and time-series database technologies and engineers who love to hack on them. If Iceberg takes over the OLAP space as the table storage format, these engineers and companies won’t just decide that area is “solved” and move to work on something else. This also won’t make sense objectively, considering that there are limitations and inefficiencies inherent to storing data only in object storage (as discussed above) and that Parquet is not the “silver bullet” file format that covers all use cases optimally.
It seems much more likely that database and data warehouse companies will start to “build around” Iceberg. For example, they can add custom-made indexes to Parquet files for specific use cases, store them in a separate SSD- or NVMe-based semi-ephemeral storage tier, or collect and cache advanced metadata outside Iceberg’s standard metadata format.
BigQuery already does this: see section 3.3 in (Levandoski et al., 2024), and Snowflake does this, too. These and other vendors will make their “accelerated Iceberg” as functional and efficient as possible, and the metadata and indexes that they propagate to the “true” Iceberg as minimal as possible, to maximise the value added by their platform and minimise the chances that their clients switch to another vendor, while keeping the right to say that they “use Iceberg” to calm customers’ concerns about the vendor lock-in.
I don’t imply that such vendors’ behaviour is wrong: all power to data warehouse vendors to build their competitive advantage!
However, in this scenario, it’s pointlessly wasteful that when users access these Iceberg layers from alternative processing engines and runtimes, bypassing the data warehouse’s native processing layers, they will not leverage the caches, indexes, and extra metadata that the data warehouse maintains anyway.
This arrangement is also not advantageous to data warehouse vendors themselves. First, they spend resources to sync their internal table metadata store with austere Iceberg metadata. Second, when users query Iceberg directly instead of using the data warehouse’s processing layer, the vendor “loses” some processing to another vendor or system, whereas if that processing was done on the vendor’s compute it would have charged the user for it.
Table transfer protocols (as well as Arrow Flight) enable interoperability between databases (data warehouses) and diverse processing engines while not inhibiting the healthy competition among the database vendors: they can use accelerated hardware setups and innovate on the approaches to data partitioning, indexing, and metadata storage while keeping their innovations proprietary if they choose to.
Databases will also retain as much processing compute as they deserve. The client can request a “thicker” or “thinner” table processing plan depending on how much the vendor will charge for these different plans, traded off with cloud provider’s egress costs (if any) of transferring smaller or larger results of the respective table processing plans, and the cost of performing the remaining processing on the client side. Similar calculations can be done for the end-to-end latency of the processing job.
The lock-in question
Another advantage of Iceberg and other open table formats I haven’t mentioned yet is that they provide an ironclad guarantee that the data team can easily move all data to another data warehouse vendor or different cloud provider. This issue is periodically raised with OLAP and timeseries databases that don’t use Parquet or ORC as their data partition file formats, such as Druid and Pinot (see example).
If the database implements Table Read protocol, there is very little extra logic they should implement (just the REPLICATION_INIT and REPLICATION_STEP RPCs: see details here) to support export/replication. Also, the database doesn’t need to run anything in its control plane to monitor the replication job.
Considering the above, it would be hard for database vendors to justify not providing this functionality to their customers: it would appear as straightforwardly anti-competitive behaviour on their part. For open-source databases, it also wouldn’t be hard for the community to implement and maintain replication RPCs for the database.
Finally, many OLAP databases already provide export to Parquet and Iceberg even though they don’t use them as their native table storage format. These databases include BigQuery, ClickHouse, Databend, Doris, StarRocks, SingleStore, Snowflake, and others. When choosing these databases, data teams can be sure they can export their data if they decide to, while table transfer protocols would enable them to enjoy the benefits of interoperability with different processing engines without paying Iceberg’s overhead.
Conclusion
I buy into the composable data systems vision (Pedreira et al., 2023; Voltron’s “Composable Codex”). However, I don’t think Apache Iceberg should be the centrepiece in the future composable data stacks for OLAP, search, and AI workloads.
Arrow Flight protocol is closer to enabling universal database and processing engine composability. However, lower-level protocols would enable the composed data systems to achieve resilience, better performance, load balancing, consistency, and other nice properties more effectively than with Arrow Flight. I’ve called such lower-level protocols table transfer protocols and drafted their design in this article series.
What vendors may be interested in table transfer protocols
Specialised and challenger database vendors who want to innovate on the storage formats and the ingestion architecture (e.g., for hybrid transactional and analytical processing, HTAP), and who realise that they cannot win the entire processing stack and therefore want to open up for diverse processing engines. I think good examples of such databases might be CedarDB, CnosDB, Druid, GreptimeDB, Hopsworks, InfluxDB, LanceDB, OpenObserve, TimescaleDB, QuestDB, Quickwit, and possibly2 Pinot, ClickHouse, Databend, Doris, Firebolt, Oxla, Pinot, SingleStore, StarRocks, and others.
Specialised and challenger processing engine vendors who are currently at a disadvantage to established technologies (Spark, Flink, and Trino) in the number of “source” and “sink” integrations. I think good examples of such processing engines might be Bodo, DataFusion, DuckDB/MotherDuck, Theseus, and others.
Accelerated and specialised hardware platform vendors who want the databases and processing engines to utilise their hardware (compute, networking, and storage) most effectively via the streaming protocol for columnar data. Cf. Nvidia’s Rapids (including cuDF) and Intel’s oneAPI Data Analytics Library (oneDAL).
High-level data systems: ETL/ELT orchestrators and schedulers, change data capture, data movement, and replication tools, semantic layers, BI and operational analytics interfaces, decision intelligence and causal inference algorithms, data science apps and frameworks, feature stores, ML training frameworks, ML inference apps and platforms, data catalogs and governance, and others. High-level data systems can interface with databases and coordinate with the processing engines more effectively with the help of table transfer protocols than with Arrow Flight, and provide better end-to-end consistency and exactly once delivery guarantees.
Project status and what’s next
The work on this article series was sponsored by Rill Data. Rill Data is interested in developing the open data ecosystem rather than promoting any specific database solution. Rill’s technology is compatible with various databases mentioned in this article series, including ClickHouse, Apache Druid, and DuckDB.
I’m interested in starting a working group to develop table transfer protocols, perhaps within the Apache Arrow project. However, this also depends on interest from the vendors of databases, processing engines, and high-level data tools. If you represent some vendor who might be interested in helping with developing table transfer protocols and supporting libraries, please drop me a line at leventov@apache.org.
Appendix: A word about “big” vs. “small” data
(Note: this section was originally published in another article in this series.)
Jordan Tigani recently demonstrated that the vast majority of teams actually don’t have “Big” data, and those who do rarely query it on a large scale, anyway. From my perspective, there is nothing to argue about here, I think Tigani is correct.
However, I design table transfer protocols specifically to address possible performance and efficiency limitations of Iceberg, even though most data teams will likely never encounter these limitations, or may save only pennies on their small workloads. Isn’t there a contradiction here?
My “theory of impact” is not that table transfer protocols will save that much money for most data teams, and query latency for most use cases. Rather, the performance and efficiency of table transfer protocols should assure data teams in choosing OLAP databases with native table storage formats instead of open table formats like Iceberg.
Data teams may think that data and query volumes may increase in the future, and therefore they need a “grown-up”, Big Data solution that is guaranteed to scale. Many of these teams end up being wrong, as Jordan Tigani finds.
My response to this is not trying to argue these data engineers out of their affinity to “big data”, object storage-based solutions. I think individual data teams are often right when they choose the data lakehouse architecture: they rationally hedge against their own risk, as the cost of industry-wide inefficiency. Table transfer protocols should help the data teams to hedge against this “scaling risk”, thus enabling them to pick more efficient solutions from the beginning.
Sometimes, a commercial cloud-based tier of an open-source database is essentially a different system because it can more easily leverage the same primitives that data warehouses from public clouds use.
However, the databases in this group seem to have ambitions to own the processing stack more thoroughly.